2018년 11월 27일
강화학습 (Reinforcement Learning)
1. 알파고의 학습 방법, 강화학습
(1) 강화학습(Reinforcement Learning)의 개념
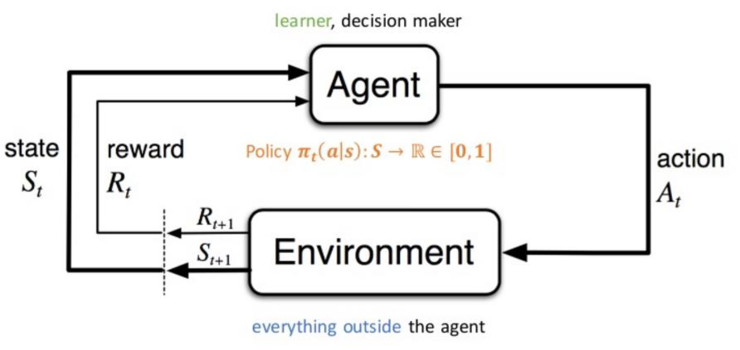 |
- 데이터의 상태를 인식하여 행위 기반 환경으로 받는 보상을 학습하여 최적화 정책 찾는 기계학습
(2) 강화학습의 필요성
- 학습/결과가 무한히 많은 경우 지도/비지도 학습 적용 어려움
- 매 순간 특정 Action 시 Reward(+1, -1)기반 최적 정책 학습
2. 강화학습의 기본원리/구성요소 및 세부 알고리즘
(1) 강화학습의 원리/구성요소
– 원리: MDP(Markov Decision Process)기반 상태 전이가 현재 상태 St와 입력(행동) At에 의해 확률적으로 결정되는 모델
| 구성요소 | 설명 | 사례 |
|---|---|---|
| State | – Agent가 인식하는 자신의 상태 State Set | – 모든 가능한 관절의 상태/환경 |
| Action | – 특정 State에서 판단에 의한 행위 | – 관절을 어떻게 Control 하는가 |
| Reward | – 주어진 상태에서 특정 Action 시 얻는 Reward | – R: S x A → R |
| Discount Factor | – 각 State 받은 Reward를 단순 증가 시 오류 발생 | – 무한대 플러스 시 크기 비교 불가 |
| Transition Probability | – 특정 행동 시 다음 상태 예측 확률 | – Psa:(st,at) → sat |
(2) 강화학습의 세부 알고리즘
| 구분 | 알고리즘 | 설명 |
|---|---|---|
| 마르 코프 | 반복 값 | – 값 함수가 수렴할 때까지 반복 |
| 반복 정책 | – 임의 정책이 수렴 까지 개선 | |
| Q-Learning | – 미래 가치(Q) 기반 활동 수행 | |
| SARSA | – 상태-활동-보상-상태-활동반복 | |
| 진화형 | 학습분류자 | – 규칙과 정책 분류 및 보상 |
| XCS | – Learning Classifier System 등 | |
| 통계적 급강하법 | – 통계기반 최적화 수행 방법 | |
| 유전 알고리즘 | – 환경에 최적화된 개체 선택 |
3. 강화학습 활용 분야
| 활용 분야 | 설명 |
|---|---|
| 로봇 제어(알파고) | – 최고의 승률을 위한 최적 경로 탐색 |
| 게임 개인화 | – 활동과 보상 기반 최적 행동 도출 |
| 공정 최적화 | – 최적의 정책 도출하여 공정을 최적화 |
| 웹 정보 검색 | – 사용자 정보요구 기반 최적 문서 선별 |
- 환경 지식의 정교한 학습 위해 Example Set 학습뿐 아니라 여러 문제 총체적 학습 능력이 필요