2018년 12월 24일
마르코프 결정 프로세스 (MDP, Markov Decision Process)
1. 최적 Policy 수립, 마르코프 결정 프로세스(MDP)
- 마르코프 결정 프로세스, MDP (Markov Decision Process)
| 개념 | 필요성 |
|---|---|
| 이산시간 확률제어 과정으로, 상태, 행동 및 전이확률 기반 최적의 의사결정 정책 을 탐색하는 강화학습 기법 | – 인공지능 판단 정책 필요 – 최적 의사결정 탐색 – AI 자율적 학습 필요 – 최적화 문제 도구로 활용 |
2. 마르코프 결정 프로세스의 전이도/구성요소 및 알고리즘
(1) 마르코프 결정 프로세스의 전이도/구성요소
| 전이도 | 구성요소 |
|---|---|
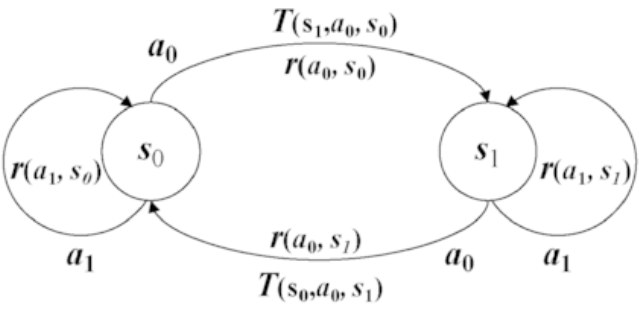 | – S: 상태의 유한 집합 – A: 행동의 유한 집합 – R: 보상 기대값, R(s, a) – r: Discount Factor (0, 1) – T: 전이확률, T(s’, a, s) |
(2) 마르코프 결정 프로세스의 주요 알고리즘
| Value Iteration (값 반복) | Policy Iteration (정책 반복) |
|---|---|
| – 동적 계획법 사용 – 함수 미사용, V(s)로 대체 – Vi(s)의 i차수 반복 수행 | – 명확한 종료 조건 – 계산 단계 1회 수행 – 수렴 시까지 V(s) 반복 |
– MDP의 핵심 문제는 최적의 의사결정 정책(policy) 를 결정하는 Exploration을 통한 Exploitation 수행
3. 마르코프 결정 프로세스와 유사 강화학습 알고리즘 비교
| 항목 | MDP | Q-Learning |
|---|---|---|
| 결정 과정 | – 전이확률T(s’,a,s) 계산 | – 미래값(Q) 계산 |
| 정책(Policy) | – π(s) = 𝑎𝑟𝑔𝑚𝑎𝑥 𝑇(𝑠’, 𝑎, 𝑠) | – π(s) = 𝑎𝑟𝑔𝑚𝑎𝑥 𝑄(𝑠, 𝑎) |
| 최적 값 | – 수렴 시까지 V(s)수행 | – Q Table 업데이트 |