2018년 12월 18일
스톰 (Apache Storm)
1. 빅데이터 실시간 처리, 스톰
(1) 스톰의 개념
- 데이터 실시간 처리를 위해 개발된 범용 분산 환경 기반 실시간 데이터 처리시스템
(2) 스톰의 특징
| 실시간 처리 | – 인메모리기반 실시간 스트리밍 처리 방식 |
| 스트리밍 | – IoT 등 지속적 발생 데이터 처리 솔루션 |
2. 스톰 아키텍처 및 구성 요소
(1) 스톰 아키텍처
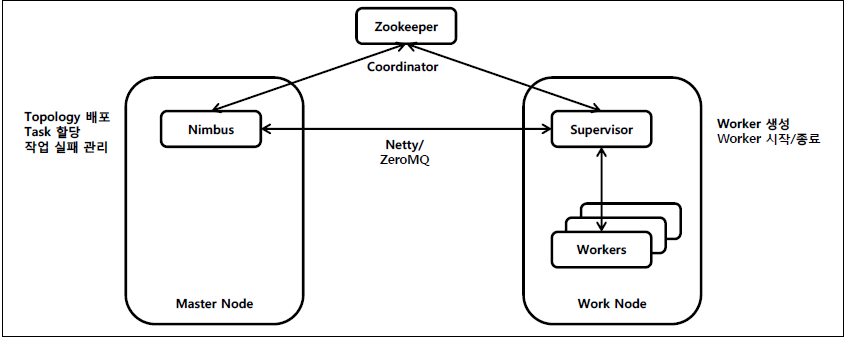 |
- 스톰의 클러스터는 마스터 노드(Nimbus)와 워커 노드(Supervis-or)로 구성, Zookeeper
(2) 스톰의 구성 요소
| 구성 요소 | 설명 |
|---|---|
| Nimbus | – 마스터 노드는 작업 할당과 실행 확인 등 관리 역할 수행 |
| Supervisor | – 워커 프로세스의 시작/종료, 실행 상태 모니터링 수행 |
| Zookeeper | – 분산 노드 관리 수행, 시스템 안정성 유지하도록 관리 역할 |
- Nimbus와 Supervisor는 Zookeeper를 통해 작업 상황 및 클러스터 상태 정보 제공
3. 스파크와 스톰의 비교
| 항목 | 스파크 | 스톰 |
|---|---|---|
| 데이터 처리 | – 일괄 처리 방식 | – 실시간 스트리밍 방식 |
| 업데이트 | – 파일 or 테이블 | – 스트림 (튜플) |
| 컴퓨팅 환경 | – 인메모리 기반 | – 인메모리 기반 |
| 반복 작업 | – 강력한 성능 | – 일반적 수준 |
| 프로그램언어 | – Scala | – Clojure |
| 사용 환경 | – 반복 & 많은 연산 | – 응답시간↓, 다양질의 |