2024년 3월 21일
어텐션 메커니즘 (Attention Mechanism)
1. 어텐션 메커니즘의 개념 및 필요성
| 개념 | seq2seq의 경사감소 소멸(Gradient Descent Vanishing) 등 RNN 모델의 문제 해결을 위해 출력 단어 예측 시점 마다 입력 시퀀스의 단어 가중치를 계산하여 정확도 감소를 보정하는 메커니즘 |
|---|---|
| 필요성 | 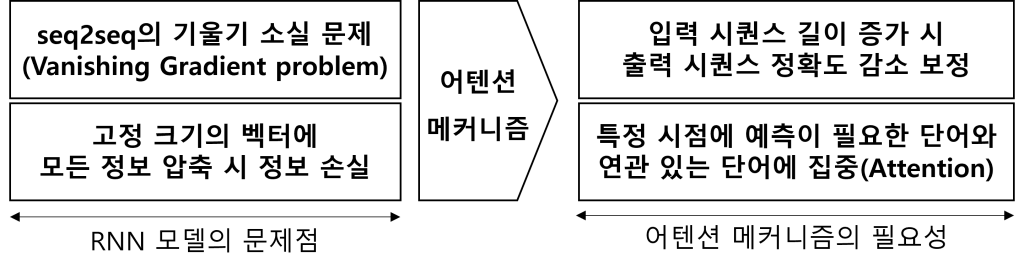 |
- 어텐션 메커니즘에서 어텐션 함수는 Softmax, Sigmoid, ReLu 함수 등 활성화 함수와 함께 사용하여 입력 시퀀스의 각 단어 가중치 계산 및 예측 벡터 도출을 통해 딥러닝 모델의 성능 향상에 활용
2. 어텐션 함수 및 예측 벡터 도출 메커니즘
(1) 어텐션 함수 (Attention Function)
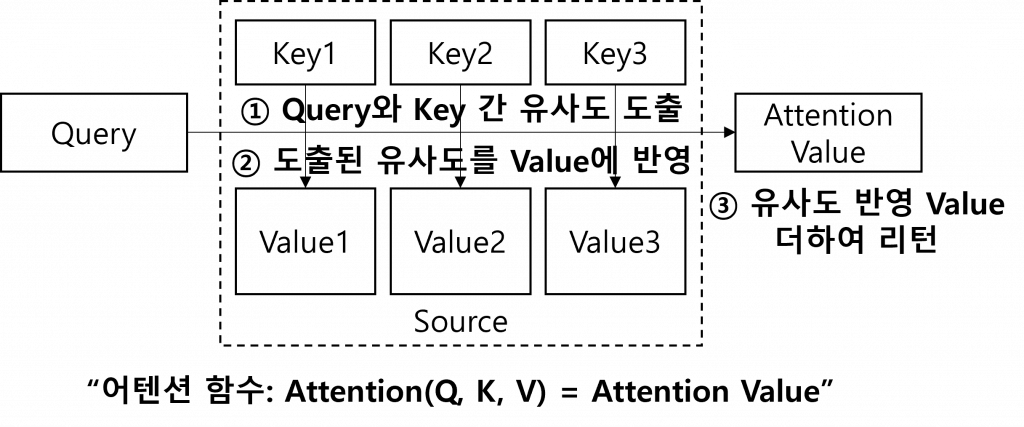 |
(2) 어텐션 함수 기반 단계별 예측 벡터 도출 메커니즘
– Dot-Product Attention 함수 적용 기준
| # | 단계 | 메커니즘 |
|---|---|---|
| ① | 어텐션 스코어 도출 (유사도 도출) | – 인코더와 디코더의 은닉상태 유사도 도출 – 단어 별 은닉상태와 내적(dot product) 수행 |
| ② | 어텐션 분포 도출 (유사도 반영) | – Softmax 함수 기반 어텐션 분포를 도출 – ①에서 단어 별 도출된 값을 어텐션 가중치로 사용 |
| ③ | 유사도 기반 어텐션 값 도출 | – ②에서 도출된 각 인코더 어텐션 가중치 기반 은닉상태 가중합하여 어텐션 값(Attention Value) 도출 |
| ④ | 디코더의 은닉 상태 연결 | – ③에서 도출된 어텐션 값을 디코더의 현시점 은닉상태와 결합하여 하나의 벡터로 생성 |
| ⑤ | 신규 벡터 신경망 연산 | – 출력층 연산의 입력이 되는 신규 벡터 계산 – ④에서 생성된 벡터에 신경망 연산 추가 |
| ⑥ | 출력층의 입력으로 사용 | – ⑤에서 추가 연산된 벡터를 출력층의 입력으로 사용하여 예측 벡터 도출 |
- 어텐션은 다양한 종류가 있으나 대부분의 어텐션 메커니즘은 유사하며 스코어(유사도) 도출 방식에 따라 차이 존재
3. 어텐션 메커니즘의 유형
| 유형 | 스코어 도출 방식 | 어텐션 함수 |
|---|---|---|
| Dot-Product Attention | Query와 Key의 내적 사용 | Score(Q, K) = QKT |
| Scaled Dot-Product Attention | 내적 값을 Key 벡터의 차원 수의 제곱근으로 나누어 스케일링 | Score(Q, K) = QKT / √dk |
| Additive Attention | Query와 Key 결합 후, 학습 가능 가중치 행렬 적용 | Score(Q, K) = vT * tanh(W1 * Q + W2 * K) |
| Multi-Head Attention | 여러 독립적 어텐션을 병렬로 수행 후 결과 결합 | MultiHead(Q, K, V) = Concat(head1, …, headh) * WO headi = Attention(Q * WQi, K * WKi, V * WVi) |
- 어텐션 메커니즘 적용에 따라 계산 비용 증가, 훈련 데이터 부족 등 한계점이 있으나 효율적 구조 설계, 합성데이터 사용 등을 통해 개선 필요
4. 어텐션 메커니즘의 문제점 및 해결방안
| 문제점 | 해결방안 |
|---|---|
| – 계산 비용과 복잡성 증가 – 입력 길이 제한, 일반화 한계 – 대용량 메모리 요구로 메모리 부족 – 대규모 훈련 데이터 부족 – 내부 동작 해석 어려움 | – 효율적인 구조 설계로 모델 성능 향상 – 어텐션 메커니즘 개선, 일반화 성능 향상 – 메모리 네트워크 기반 장기 의존성 문제 해결 – 합성데이터 사용 및 전이학습 – 자가-어텐션 메커니즘 기반 데이터 구조 파악 |
- 최근 멀티헤드 어텐션(Multi-head Attention) 메커니즘이 활발히 연구에 활용되고 있으며, 특히 트랜스포머(Transformer) 딥러닝 아키텍처에 주로 활용되어 ChatGPT 등 대규모 언어모델 기반 생성형AI 서비스에 적용
[참고]
- wikidocs, 딥 러닝을 이용한 자연어 처리 입문