2023년 2월 5일
엣지 AI (Edge AI)
1. 단말 장치 자체 AI 서비스, 엣지 AI (Edge AI)의 개념
| 개념도 | 개념 |
|---|---|
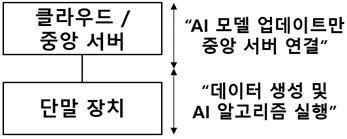 | IoT, 모바일 장치 등 단말 장치의 신속한 인공지능 서비스를 위해 단말 장치에서 생성한 데이터로 AI 알고리즘을 직접 실행하는 분산형 컴퓨팅 패러다임 |
- 단말장치에서 데이터생성과 AI 알고리즘 처리를 지원하므로 AI 모델 업데이트 시에만 중앙서버 연결, 온디바이스 AI(On-Device AI) 방식이 대표적
2. 엣지 AI 구현 메커니즘 및 주요 기술
(1) 엣지 AI 구현 메커니즘
| 메커니즘 | 구현 절차 |
|---|---|
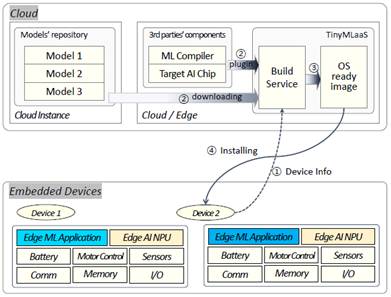 | ① CPU 유형, RAM/ROM 크기, 주변 디바이스, 기본 소프트웨어 등 디바이스 정보 수집 |
| ② 적합한 머신러닝 컴파일러 선택 및 모델 저장소에서 AI 모델 다운로드 | |
| ③ 매개변수 기반 컴파일된 머신러닝 추론 모듈 생성 | |
| ④ 생성된 머신러닝 추론 모듈 배포, 디바이스에서 배포된 모듈 기반 AI 알고리즘 실행 |
- 엣지 AI 구현 위해 클라우드 및 중앙 서버에서 AI 모델 업데이트 이후 디바이스 자체 AI 알고리즘 실행
(2) 엣지 AI의 주요 기술
| 구분 | 주요 기술 | 기능 및 세부 기술 |
|---|---|---|
| 엣지 AI 기반 기술 | 엣지 AI 프레임워크 | – 단말 장치용 초소형 엣지 머신러닝 모델 개발 프레임워크 – TensorFlow Lite, Embedded Learning Library, ARM-NN 등 |
| AutoML | – 데이터 준비, 모델 생성, 모델 평가 등 주요 단계 자동화 – AutoKeras, Edge Impulse, NNI(NeuralNetworkIntelligence) | |
| 단말 장치 AI 모델 압축 | 모델 양자화 | – 모델 파라미터 크기나 연산 수 최소화 위한 가중치 정밀화 – 신경망 가중치 이진화(Binarization), int4/int2 변환 등 |
| 인지형 가지치기 | – 낮은 중요도 및 중복되는 뉴런 제거를 통한 압축 모델 생성 – 필터/채널 제거(구조적), 개별 가중치 선택(비구조적) | |
| 인지형 NAS (Neural Architecture Search) | – 대상 H/W 특성 기반 최적 성능 적응형 신경망 설계 자동화 – 지연시간, 전력소비 등 성능지표와 정확도 간 균형모델설계 | |
| 엣지 AI 적용 /운영 | 엣지 AI 모델 컴파일 | – 코드 최적화, H/W 파편화에 따른 명령어 세트 대응 컴파일 – NET-C, TensorFlow XLA, ONNC, nGraph,Glow,TVM,PlaidML |
| MLOps | – 무중단 업데이트, 지속 전달 및 피드백 루프 배포주기 조정 – 머신러닝CI/CD파이프라인에 CT(Continuous Training)추가 |
- AI 서비스는 네트워크 코어에서 엣지로 꾸준히 이동하고 있어 초소형 디바이스 지능화를 위한 머신러닝 기술이 발전되고 있으나 하드웨어 파편화 및 성능 제약에 따라 클라우드/중앙집중형 AI와 상호 보완 필요
3. 엣지 AI와 클라우드/중앙집중형 AI 비교
| 비교 항목 | 엣지 AI | 클라우드/중앙집중형 AI |
|---|---|---|
| AI 알고리즘 실행 위치 | 로컬 컴퓨터, 임베디드 시스템 | 클라우드, 중앙 서버 |
| AI 서비스 공급자 | 하드웨어 공급자 중심 (System-On-Chip) | 소프트웨어 공급자 중심 |
| AI 모델 생성 목표 | 모델 최소화, 성능과 정확도 간 균형 | 모델 최적화, 정확도에 중점 |
| 장점 | 지연시간 감소, 오프라인 가용성 확보 | 서비스 접근성, 운영 효율성 제고 |
| 한계점 | 하드웨어 파편화, 성능 및 AI모델 제약 | 통신 인프라 의존, 개인정보 보호 이슈 |
- 엣지 AI는 정보보호, 지연시간 절감, 오프라인 가용성 확보 등의 장점이 있지만 AI 모델 적용 및 디바이스 사양에 따른 한계가 존재하므로 클라우드/중앙집중형 AI와 상호 보완하는 형태로 발전 예상
[참고]
- 한국전자통신연구원(ETRI), “서비스형 엣지 머신러닝 기술 동향”
- 정보통신정책연구원(KISDI), “클라우드 기반 AI에 대한 엣지 AI의 도전과 영향”