2018년 12월 12일
오버핏과 언더핏 (Overfitting & Underfitting)
1. 과한 학습과 부족 학습, 오버핏과 언더핏의 문제점
| 구분 | 문제점 | 현상 |
|---|---|---|
| Overfit (과분산, 과적합) | – 과학습, 오류 분산 – High Variance, 과분산 – 비슷한 입력에 부정확 반응 결과 | 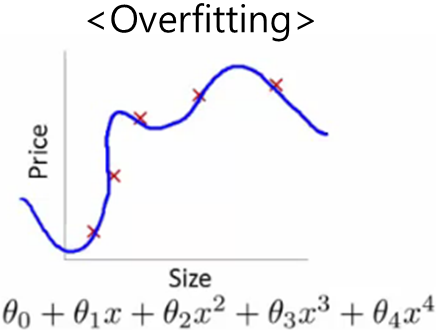 – 학습 대상만 정상반응 |
| Underfit (과편향) | – 데이터해석 능력저하 – High bias, 과편향 – 여러 가지 입력에 제대로 반응불가 | 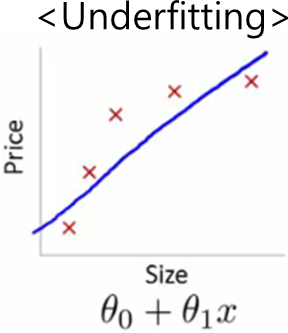 – 학습 부족, 편향 반응 |
- 오버핏과 언더핏의 공통적인 문제점으로 예측 성능(Serendipity) 저하 현상 발생
2. 오버핏과 언더핏 원인 별 대응방안
| 구분 | 원인 | 대응 방안 |
|---|---|---|
| 오버핏 | – 편중된 학습 데이터 | – 다양한 훈련 데이터확보 |
| – Too many Features | – 정규화, 표준화 | |
| – 무분별한 Noise 수용 | – Dropout(일부 뉴런 생략) | |
| 언더핏 | – 부적절한 분석 모형 | – 분석 모델 유연성 확보 |
| – 학습 데이터 부족 | – 충분한 학습데이터 확보 | |
| – 표준 집합 부족 | – Cross Validation |
- 오버핏과 언더핏은 Trade-off 관계이므로 적절한 훈련 데이터셋을 통해 최적의 값 파악 필요
3. 오버핏과 언더핏 방지를 위한 고려사항
| 고려사항 | 설명 |
|---|---|
| – Training Data Set 최적 값 선정 | – 충분한 Training Data Set 확보 – Noise 고려하여 적절한 분포도 필요 |
| – 학습 대상, 데이터 의 적절한 Feature | – 대상 별 적절한 Feature 수 선정 – 원하는 분석모형 고려하여 일반화 |