2024년 3월 9일
대규모 언어 모델 (LLM, Large Language Model)
1. 대규모 언어 모델 (LLM, Large Language Model) 개요
(1) 대규모 언어 모델의 등장 배경
 |
(2) 대규모 언어 모델의 개념 및 특징
| 개념 | 특징 |
|---|---|
| 인간의 언어 이해와 생성을 위해 대량의 언어 데이터 학습, 파인튜닝하여 생성된 인공신경망 기반 생성형AI 언어 모델 | – LLM은 대량의 언어 데이터로 훈련하여 맥락 파악 후 적절한 응답을 생성 – 한 단어가 끝나고 다음 단어 예측 시 단어 사이 유사성, 문맥 파악하여 정확한 의미 생성 |
2. 대규모 언어 모델(LLM)의 구조 및 유형
(1) 대규모 언어 모델의 Encoder-Decoder 구조
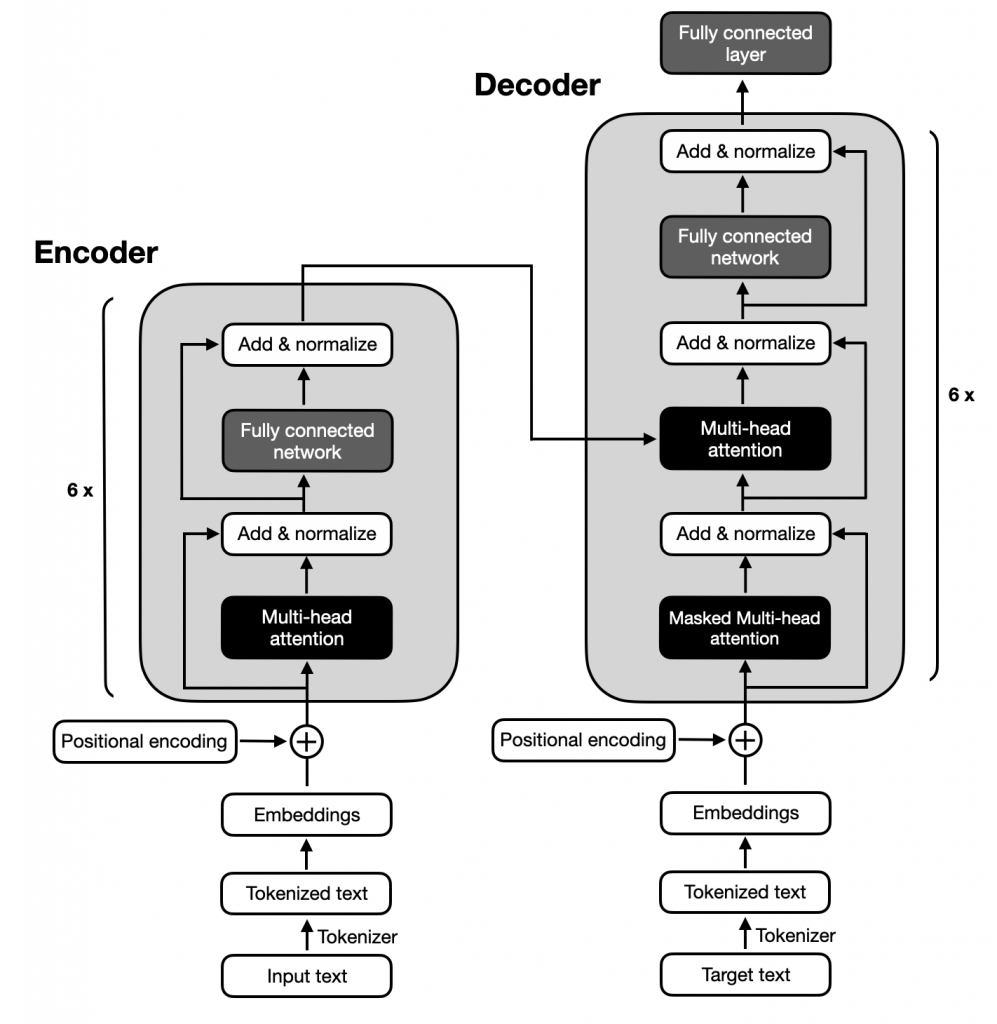 |
(2) 대규모 언어 모델의 유형
| 유형 | 메커니즘 | 주요 모델 |
|---|---|---|
| Encoder 모델 | – Transformer의 encoder만 사용 – encoder의 어텐션 레이어가 초기 문장의 모든 단어에 접근 – 주어진 문장 중 임의 단어 masking 후 원래 문장을 찾거나 복원 – 전체 문장의 이해를 요구하는 task에 적합 | – BERT (Google) |
| Decoder 모델 | – Transformer의 decoder만 사용 – decoder의 어텐션 레이어는 문장 내 단어 바로 앞 단어만 접근 – 문장의 다음 단어 예측 중심, 텍스트 생성 관련 task에 적합 | – GPT (OpenAI) – LLaMA (Meta) |
| Encoder-Decoder 모델 | – Transformer의 encoder와 decoder를 모두 사용 – encoder의 어텐션 레이어는 초기 문장 모든 단어에 접근 – decoder의 어텐션 레이어는 입력에 주어진 단어 앞 단어만 접근 – 새로운 문장을 생성하는 요약, 번역, 생성적 질문 답변에 적합 | – BART (Meta) |
3. 대규모 언어 모델(LLM)의 구성 요소 및 기술 요소
(1) 대규모 언어 모델의 구성 요소
| 구분 | 구성 요소 | 역할 |
|---|---|---|
| 기반 요소 | 파라미터 | – 신경망 모델의 가중치를 결정하는 매개변수 |
| 토큰 | – LLM이 인식하는 문자 데이터 단위(형태소) | |
| 파운데이션 모델 | – 일반 작업을 수행할 수 있는 기초 AI모델 | |
| 인공신경망 | 임베딩 레이어 | – 입력 텍스트로부터 의미론적 임베딩 생성 |
| 순환 신경망 | – 현재/과거 데이터를 고려하여 순차 데이터 처리 | |
| 어텐션 메커니즘 | – 입력 시퀀스의 다양한 부분에 가중치를 부여 |
(2) 대규모 언어 모델의 기술 요소
| 구분 | 기술 요소 | 메커니즘 |
|---|---|---|
| 학습 모델 | 제로샷 러닝 | – 프롬프트를 통해 명시적 훈련 없이 요청에 응답 |
| 퓨샷 러닝 | – 적은 데이터를 통해 새로운 작업, 도메인 학습 | |
| 파인튜닝 | – 용도에 따라 LLM 미세 조정 과정(후처리) | |
| 프레임워크 | 랭체인 | – 에이전트, 콜백 등 기능 연결 및 통합 간소화 |
| 벡터DB | – 벡터 임베딩, 유사도 기반 신속 인덱싱 DB | |
| 프롬프트 엔지니어링 | – 원하는 결과 제공받기 위해 프롬프트 설계, 제작 |
- 대규모 언어 모델은 대량의 언어 데이터 학습 및 인공신경망 활용에 따른 개인 정보 유출, 환각 현상 등의 문제점이 발생할 수 있으므로 검색 증강 생성(RAG), 합성데이터 등 사용 필요
4. 대규모 언어 모델의 서비스 계보 및 문제점/대응방안
(1) 대규모 언어 모델의 서비스 계보 (2018~2023)
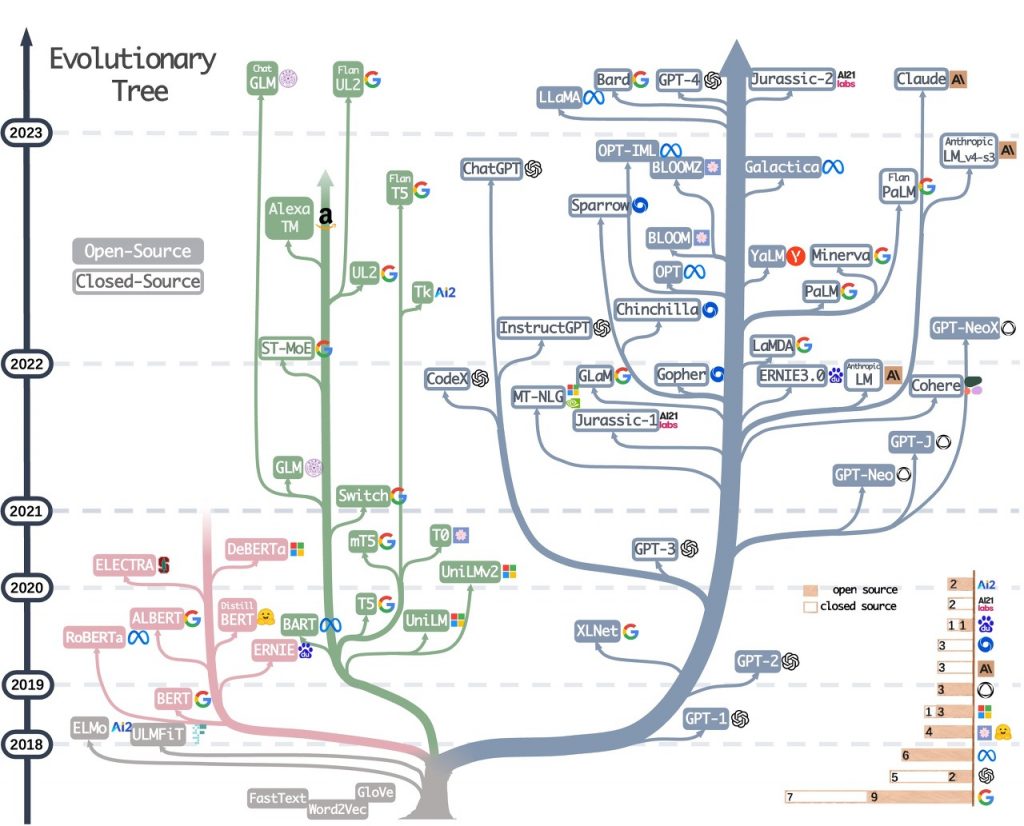 |
(2) 대규모 언어 모델 활용 시 문제점/대응 방안
| 문제점 | 대응 방안 |
|---|---|
| – 검증되지 않은 응답 생성(환각 현상) – 훈련 데이터 확보 어려움, 개인정보 유출 – 편향된 결과 및 응답 품질 저하 발생 – 대규모 언어 모델 확장/배포 어려움 | – 신뢰 지식베이스 기반 검색 증강 생성(RAG) – 개인 정보 없이 실제와 유사한 합성데이터 사용 – 프롬프트 엔지니어링 기반 최적 입력 설계 – 랭체인, 벡터DB 등 기반 프레임워크 적용 |
- 대규모 언어 모델은 인공신경망 기반으로 동작하므로 정확한 동작 메커니즘은 아직 알려지지 않았으며, 윤리적인 문제 발생 가능성에 대비하여 생성형 AI 윤리 가이드를 통해 부작용 방지 필요
[참고]
- 한국인공지능협회, 초대규모 모델 의 AI (GPT-3) 부상과 대응 방안
- Amazon Web Services, 대규모 언어 모델(LLM)이란 무엇인가요