2024년 3월 5일
유사도 측정법 (Similarity Measure)
1. 유사도(Similarity)의 개념 및 유사도 측정의 필요성
| 유사도 (Similarity) | 유사도 측정의 필요성 |
|---|---|
| 벡터 공간 내 노드(데이터 포인트) 사이의 관계를 거리, 각도 등을 통해 수치화하여 정량적으로 표현한 유사성 척도 | – 데이터 간 유사도 측정 기준 제공 – AI 데이터 라벨링, 모델 학습 및 진단 – AI 데이터세트의 오류, 편향 탐지 |
- 벡터 공간 내 노드의 크기(강도, 길이) 척도를 나타내는 노름(Norm)을 통해 데이터 간 거리 측정 가능
- 거리와 관계 기반 유사도 측정 기법을 통해 데이터 포인트를 다차원 공간에서 벡터로 표현하여 의미적 유사도 측정 가능하며, 워드 임베딩을 통해 학습 데이터 생성 및 유사도 검색 가능
2. 거리 기반 유사도 측정법의 유형
(1) 유클리디안 거리 (Euclidean Distance)
| 개념 | 벡터 공간 내 두 노드 사이의 직선 거리를 이용하여 유사도를 산출하는 벡터 거리 기반 유사도 측정법 |
|---|---|
| 개념도 | 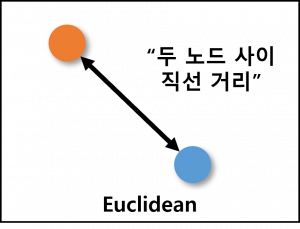 |
| 특징 | – 두 노드 사이의 직선 거리를 통해 최단 거리 도출 – 가장 단순하며 일반적으로 사용하고 유클리드 공간을 정의 |
| 산출식 | 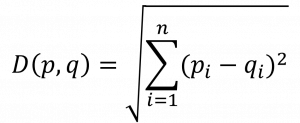 |
(2) 맨해튼 거리 (Manhattan Distance)
| 개념 | 벡터 공간 내 두 노드 사이의 수평 및 수직 이동 거리의 합으로 유사도를 산출하는 벡터 거리 기반 유사도 측정법 |
|---|---|
| 개념도 | 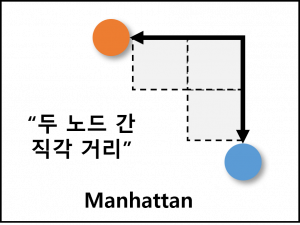 |
| 특징 | – 수평 및 수직 방향으로의 이동만 측정하여 거리 산출 (대각선 방향은 고려하지 않음) – 두 노드 사이 차원 실수를 데카르트 좌표계의 일정한 좌표축에 투영한 선분 길이의 합 |
| 산출식 | 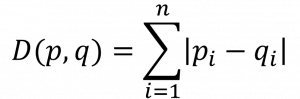 |
(3) 체비쇼프 거리 (Chebyshev Distance)
| 개념 | 벡터 공간 내 두 노드 사이의 좌표 차원에 따라 가장 긴 거리를 선택하는 벡터 거리 기반 유사도 측정법 |
|---|---|
| 개념도 | 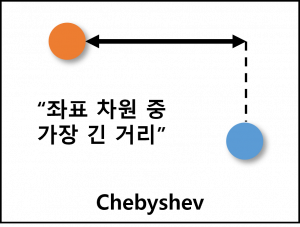 |
| 특징 | – 좌표 차원 중 긴 거리 선택 (예, x축과 y축 중 x축(수평) 길이가 길다면 x축 길이 선택) – 유클리디안, 맨해튼에 비해 사용 케이스는 한정적이나 최소한의 이동 횟수 도출 용이 |
| 산출식 |
(4) 민코프스키 거리 (Minkowski Distance)
| 개념 | 벡터 공간 내 두 노드 사이의 거리 기반 유사도 측정법을 일반화하여 유사도를 산출하는 벡터 거리 기반 유사도 측정법 |
|---|---|
| 개념도 |  |
| 특징 | – 유클리디안, 맨해튼, 체비쇼프 거리를 일반화 하여 가장 크게 떨어진 수치로 수렴 – 적절한 차원의 수를 적용하여 가장 적합한 유사도 측정 가능 |
| 산출식 | 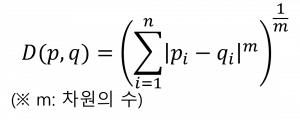 |
(5) 하버사인 거리 (Haversine Distance)
| 개념 | 두 노드 사이의 지구의 곡률을 반영한 거리를 이용하여 유사도를 산출하는 벡터 거리 기반 유사도 측정법 |
|---|---|
| 개념도 | 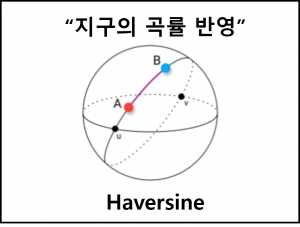 |
| 특징 | – 임의의 벡터 공간이 아닌 지구의 곡률 특성을 반영하여 실제 좌표 간 거리를 도출 – 지리 정보와 관련된 좌표 측정에 사용하며, 네비게이션 및 GPS S/W에서 사용 |
| 산출식 |  |
3. 관계 기반 유사도 측정법의 유형
(1) 코사인 유사도 (Cosine Similarity)
| 개념 | 벡터 공간 내 두 노드 사이의 코사인 각도를 이용하여 유사도를 산출하는 벡터 내적 기반 유사도 측정법 |
|---|---|
| 개념도 | 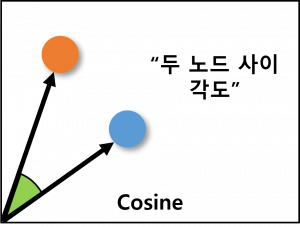 |
| 특징 | – 기울기와 방향이 같은 노드가 유사도 높은 것으로 측정 (거리는 고려하지 않음) – 고차원 데이터나 크기가 중요하지 않은 유사도 측정 시 사용 |
| 산출식 | 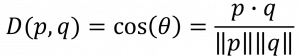 |
(2) 해밍 거리 (Hamming Distance)
| 개념 | 같은 길이를 가진 두 비트열에 대해 같은 위치에서 서로 다른 기호의 개 수(Hamming Weight)로 산출하는 유사도 측정법 |
| 개념도 | 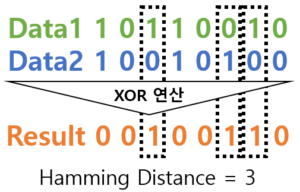 |
| 특징 | – 두 문자열을 동일 문자열로 바꾸기 위해 변경 필요한 거리, 두 문장 간 편집거리 측정 – 두 비트열 간 유사도를 수치화하여 송/수신 데이터 오류 검출 및 오류 정정 가능 – 비교 대상의 두 데이터 길이가 다를 경우 사용 어려움 |
| 산출식 | 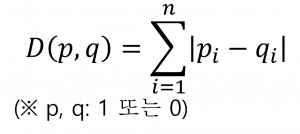 |
(3) 자카드 인덱스 (Jaccard Index)
| 개념 | 두 원소 집합 사이의 관계를 합집합과 교집합의 비율로 유사도를 산출하는 관계 기반 유사도 측정법 |
|---|---|
| 개념도 |  |
| 특징 | – 두 집합이 동일하면 자카드 유사도가 1이며, 동일한 부분이 없으면 자카드 유사도는 0 – 특정 단어 중복 시 얼마나 다른 종류의 단어가 중복되는지에 따라 문서 유사도 계산 – 자연어 처리에서 중복된 단어의 종류에 집중하고, 단어 별 중복 횟수는 고려하지 않음 |
| 산출식 | 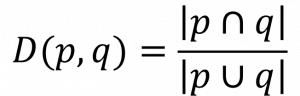 |
(4) 소렌슨-다이스 인덱스 (Sørensen-Dice Index)
| 개념 | 두 원소 집합 사이의 관계를 공통 원소 수와 평균 원소 수의 비율로 유사도를 산출하는 관계 기반 유사도 측정법 |
|---|---|
| 개념도 | 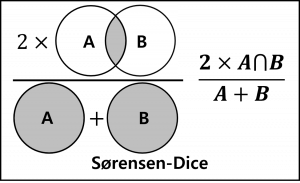 |
| 특징 | – 두 집합의 공통 원소 수를 두 집합의 평균 원소 수로 나누어 계산하는 방식 – 자연어 처리와 영상 분할에 사용하며, 계산이 직관적이고 F1 Score와 유사 |
| 산출식 | 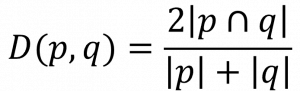 |
- 벡터 공간 내 유사도 측정 시 고차원 데이터 처리 문제점, 거리 측정 기준 등 고려사항이 존재하며, 주성분 분석(PCA), 데이터 전처리 등을 통해 해결 가능
4. 유사도 측정 시 고려사항 및 해결 방안
| 구분 | 고려사항 | 해결 방안 |
|---|---|---|
| 고차원 데이터 처리 문제점 | – 차원의 저주 발생으로 성능 저하 – 특징, 크기가 유사도 계산에 영향 | – 주성분 분석(PCA), t-SNE 기법 등 – 데이터 전처리 수행(정규화 등) |
| 측정 기준 선택 어려움 | – 분야에 특화된 측정 기준 모호 – 유사도 측정 기준 설계 어려움 | – App 요구사항 기반 측정 기준 설계 – 데이터 특성 기반 동적 유사도 측정 |
| 인덱싱 및 저장소 요구 | – 고차원 데이터 대용량 저장소 필요 – 인덱싱 효율성과 저장소 Trade-off | – 적절한 인덱싱 구조, 압축기법 선택 – 근사 인덱싱, 신경망 해싱 적용 |
- 유사도 측정은 머신러닝의 필수 요소이며, 정확하고 효율적인 데이터 분석 가능하나 고차원 데이터 및 확장성 문제 극복 위해 차원 축소, 인덱싱 등 필요
[참고]
- towards data science, 9 Distance Measures in Data Science
- DEVOCEAN, What is Vector Similarity Search