2018년 12월 19일
카프카 (Kafka)
1. 대용량 실시간 로그 처리, 카프카 (Kafka)
(1) 카프카 (Kafka)의 개념
- 대용량 실시간 처리 위한 확장성과 고가용성을 가지는 publish-subscribe 구조의 오픈소스 분산 메시징 시스템
(2) 카프카의 특징
| 비휘발성 메시지 | – 디스크 구조로 설계, 별도의 설정하지 않아도 데이터 영속성 보장 |
| TCP 기반 프로토콜 | – TCP 기반의 프로토콜을 사용하여 프로토콜에 의한 오버헤드 감소 |
2. 카프카 아키텍처 및 구성 요소
(1) 카프카의 아키텍처
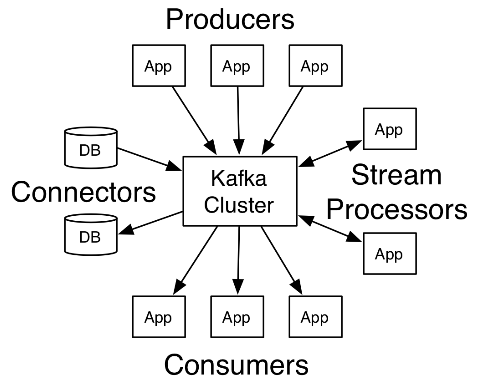 |
(2) 카프카의 구성요소
| 구분 | 구성요소 | 설명 |
|---|---|---|
| 데이터 | 레코드 | – Key, Value, Timestamp 구성 |
| 토픽 | – 레코드가 게시되는 카테고리나 피드 | |
| 파티션 | – 토픽이 쪼개져 각 서버에 저장되는 단위 | |
| Core API | Producer API | – 카프카 토픽에 스트림 레코드 게시 |
| Consumer API | – 토픽 구독 및 생성 레코드 스트림 처리 | |
| Streams API | – 스트림 프로세서로 동작, 입력→출력 스트림으로 효율적 변환 | |
| Connector API | – 재사용 가능한 프로듀서나 컨슈머를 만들고 실행 |
3. 카프카를 활용한 실시간 데이터 처리 시스템 구축 방안
