2018년 11월 23일
키(Key) 유형
1. 키(Key) 유형
(1) 키(Key)의 정의
- 데이터베이스에서 조건을 만족하는 튜플(레코드)을 찾거나 순서대로 정렬할 때 기준이 되는 속성
(2) 키(Key) 유형
| 키(Key) | 설명 |
|---|---|
| 후보키 (Candidate Key) | 릴레이션(테이블)을 구성하는 속성 중 튜플(레코드)을 유일하게 식별할 수 있는 속성의 부분 집합 |
| 기본키 (Primary Key) | 후보키 중 유일성과 최소성을 가지며 튜플(레코드)을 식별하기 위해 반드시 필요한 키, Null 값 불가 |
| 대체키 (Alternate Key) | 후보키 중 기본키를 제외한 나머지 후보키 |
| 슈퍼키 (Super Key) | 복합키 또는 연결키라고 하며, 기본키로 사용되며 2개 이상의 열을 1개의 후보키로 만들어 기본키로 사용 |
| 외래키 (Foreign Key) | 다른 릴레이션(테이블)의 기본키를 참조하는 속성 또는 속성들의 집합 |
2. Primary Key와 Unique Index 비교
(1) Primary Key와 Unique Index의 개념
| PK(Primary Key) | UI(Unique Index) |
|---|---|
| 테이블에 저장된 레코드를 식별하는 후보 키 중 기본키로 지정된 키 | 컬럼 내 중복 데이터 비허용 인덱스 – PK 정의 시 UI 자동 생성 |
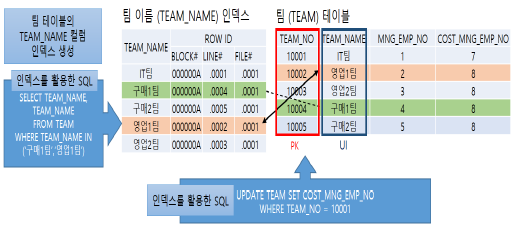 | |
(2) Primary Key와 Unique Index의 특성 비교
| 항목 | Primary Key | Unique Index |
|---|---|---|
| 목적 | 튜플 구분 및 식별 | 신속한 조회 |
| 특징 | Constraint + Index | Index |
| 공통점 | 유일성 보장 | 유일성 보장 |
| 참조 무결성 | PK/FK에 의해 지정 | 지정 불가능 |
| 테이블당 개수 | 1개만 가능 | 여러 개 가능 |
| 인덱스 생성 | Unique Index | Unique Index |
| 역공학 적용시 | PK인식 | PK인식 불가능 |
| Null 허용 | Not Null | Null 허용 |
| 조건 쿼리 | PK대상 검색 시 성능 향상 | Full Scan 발생 |
– Unique Index만 사용 시 데이터 모델 파악이 어렵고 참조 무결성 제약 조건 불가능
(3) Primary Key 사용 시 장점
| 구분 | 장점 | 내용 |
|---|---|---|
| 무결성 | 무결성 제약조건 지정 가능 | – 전체 DB에 대한 PK/FK 관계 설정 가능 – 참조 무결성 제약조건 지정 가능 |
| 무결성 오류 방지 | – 무결성 제약 조건 기반 무결성 오류 방지 – 무결성 오류에 따른 업무 혼란 방지 | |
| 유일성 | 유일성 보장 | – 전체 튜플에 대한 유일성 보장 – 테이블에 대한 정체성 구별 |
| Not Null | – PK속성에 대해 Null 허용 불가 – Null 값으로 인한 중복 튜플 발생 방지 | |
| PK | PK 구분 가능 | – 데이터 역공학 시 Primary Key 인식 가능 – DB 옵티마이저 적용 시 PK인식 가능 |
3. Primary Key 및 Unique Index 설계 시 고려사항
| 고려사항 | 내용 |
|---|---|
| 작은 데이터 타입 PK 정의 | – 최대한 작은 데이터 타입으로 PK 정의 |
| PK는 auto_incre. 사용 | – PK 속성으로 auto_increment 사용 |
| 인덱스 개수 최소화 | – 인덱스도 자원을 소모하므로 성능에 영향 |
| 인덱스 컬럼 분포도 고려 | – 데이터의 중복이 없을수록 인덱스 효과적 |
| DB엔진 별 인덱스 특성 | – InnoDB, MyISAM의 PK 인덱스 특성 고려 |