2018년 12월 19일
탐험을 위한 액션 선택
1. 탐험을 위한 액션 선택의 필요성
- AI 에이전트는 강화학습을 위해 최대한 많은 경험과 최적의 정책 결정 위한 액션 선택 필요
2. 탐험을 위한 액션선택 방법의 개념과 선택 기준
| 방법 | 개념 | 액션기준 / 구성요소 |
|---|---|---|
| 그리디 접근법 | – 현재 순간 최대 보상 기대하는 환경 보상 구조 기반 액션 선택 방법 | – 현재시점 보상치 – 최대 보상 추정치 |
| – 환경 보상 변수 – 모든 해, 후보 해 | ||
| 랜덤 접근법 | – 시점 및 보상 추정과 관계없이 랜덤 액션 및 랜덤 학습 기반 액션선택 방법 | – 보상치와 무관 – 랜덤 선택 확률 |
| – 랜덤 확률 변수 – RNG 기반 난수 | ||
| 앱실론 그리디 접근법 | – 그리디와 랜덤 접근법을 결합하여 보상 기반 일정 확률 무작위 액션선택 방법 | – 현재시점 보상치 – 랜덤 선택 확률 |
| – 랜덤확률 매개변수 – 랜덤 확률 변수 | ||
| 볼츠만 접근법 | – 다른 액션 선택 정보 고려한 소프트맥스기반 가중 확률 액션선택 방법 | – 액션 가중 확률 – 각 액션 별 추정값 |
| – 소프트맥스 – 점감 매개변수 | ||
| 베이지언 접근법 | – 액션에 대한 불확실성을 최대 이용하여 BNN기반 확률적 액션선택 방법 | – 액션의 불확실성 – 가중치 확률분포 |
| – Dropout 기법 – 신경망 반복 표본 |
- 각 액션선택 방법 별 장단점 기반 최적의 정책 및 최대 보상선택 필요, 선택 시 고려사항 존재
3. 탐험을 위한 액션선택 방법 별 장단점 비교
| 방법 | 장점 | 단점 |
|---|---|---|
| 그리디 접근법 | – 현재 시점에 대한 보상 최대화 가능 – 구현 간단, 고속학습 | – 액션 선택 시 일반적 차선 해에 도달 – 순서 기반 최적 행동 학습 불가 |
| 랜덤 접근법 | – 풍부한 경험 수집 – 상태 공간으로부터 평균 초기화 시 유용 | – 장기간 학습 필요 – 학습 예측 불가 – 보상치와 관계없는 해에 도달 |
| 앱실론 그리디 접근법 | – 수행 단순 + 효과성 – 적응적 확률 기법 – 기반 초반 탐험촉진 후반 안정화 | – 랜덤 확률 추가 계산 – 단순 액션 기반 보상 여부만 고려 |
| 볼츠만 접근법 | – 타 액션선택 고려 – 차선 액션 제외가능 – 잠재적 유망 선택 – 에이전트 확신 척도 | – 액션 기반 에이전트 불확실성 이해부족 – 에이전트 확신척도는 최선 정책이 아님 |
| 베이지언 접근법 | – 불확실 추정치 도출 – 가중치확률분포 유지 – 높은 보상 획득률 | – 다수 표본추출 필요 – 계산 복잡도 증가 – Dropout 추가계산 – 노이즈에 영향 |
- 인간의 액션 선택 메커니즘과 같이 타 액션에 대한 불확실성 도출 및 확률 기반 최적 선택 고려 필요
4. 최적의 액션선택 방안 및 고려사항
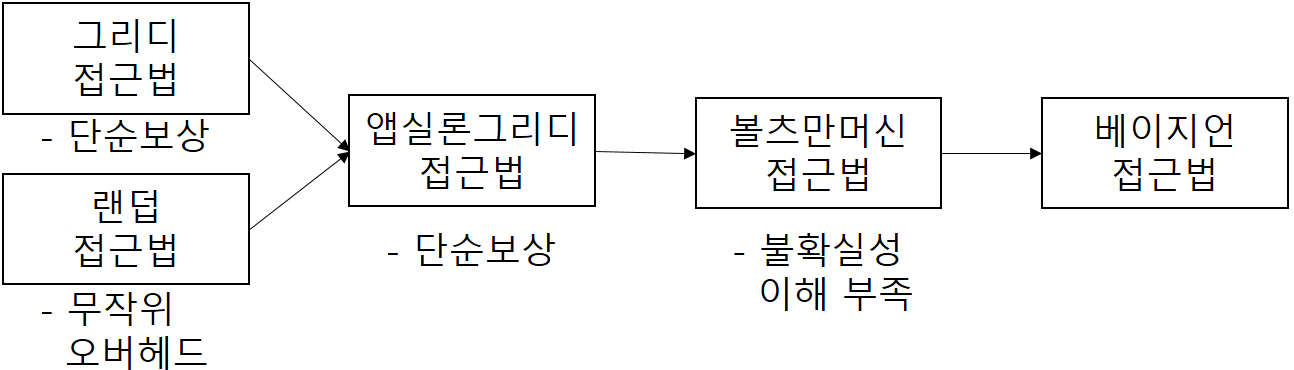 |
- 볼츠만, 베이지언 기법이 타 기법의 단점을 보완, 유용하며, 그리디, 랜덤 기법은 기반 기술로 활용