2023년 11월 5일
합성 데이터 (Synthetic Data)
1. AI 학습 데이터 부족 문제 해결, 합성 데이터의 개요
(1) 합성 데이터의 개념
| 개념도 | 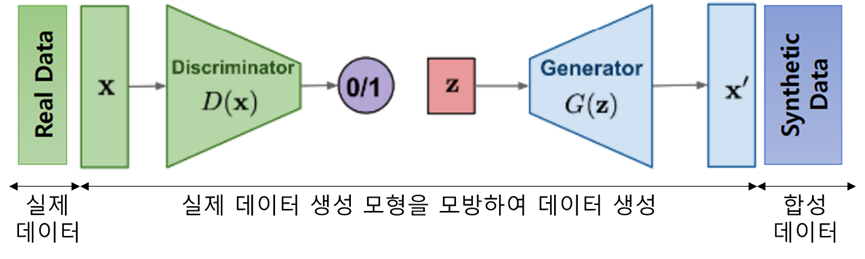 |
|---|---|
| 개념 | 개인정보 보호 및 고품질의 충분한 학습 데이터 확보를 위해 실제 데이터의 생성 모형 및 패턴을 모방하여 실제 데이터와 유사한 통계 속성을 가지고 생성된 모의 데이터 |
(2) 합성 데이터의 필요성
| 실제 데이터 사용 시 제약사항 | 합성 데이터의 필요 |
|---|---|
| – 개인정보 보호 등의 이유로 데이터 접근 제한 – 데이터 정제(노이즈 제거)에 시간/노력 소요 – 정확성, 완전성 등 고품질 데이터 수집 어려움 – 불충분데이터는 AI 모델 과소/과대 적합초래 | – 임의 생성 데이터로 개인정보 규제 미적용 – 모집단의 통계 특성 유지, 민감정보 유출 방지 – 완전한 데이터 생성으로 정제 과정 불필요 – 충분한 양의 고품질 데이터 확보 가능 |
- 데이터는 원유에 비유될 정도로 중요하며 인공지능 기반 혁신 달성 위해 합성 데이터가 반드시 필요
2. 합성 데이터 생성 방법 및 품질 평가 방안
(1) 합성 데이터 생성 방법
| 구분 | 생성 방법 | 생성 원리 |
|---|---|---|
| 실제 데이터 유무 측면 | 실제 데이터 없이 생성 | – 기존 개발된 모델 또는 분석가 지식 기반 생성 – 통계적 모델, 설문조사, 기타 데이터 수집 메커니즘 |
| 실제 데이터 기반 생성 | – 데이터를 설명하는 생성 모델 기반 합성 데이터 생성 – 소스데이터 → 설명모델 → 모델적용 → 합성 데이터 | |
| 신경망 활용 측면 | 임베딩 기반 생성 | – 인코더(원본 압축) → 디코더(데이터 세트 출력) – 시스템 학습은 입출력 데이터 간 상관관계를 최대화 |
| GAN 기반 생성 | – 생성자는 실제와 유사한 데이터 생성, 판별자는 실제 데이터와 구별 시도 기반 고품질 합성 데이터 생성 |
- 변수 별 데이터 세트 변수를 합성하는 순차적 합성(Sequential synthesis) 등의 생성 방법도 존재
(2) 합성 데이터 품질 평가 방안
| 구분 | 품질 평가 방안 | 품질 평가 방법 |
|---|---|---|
| 데이터 비교 측면 | 분산 비교 | 실제와 합성 데이터 간 분산 비교, 변수별 대표성 비교 |
| 식별력 활용 | 개발된 모델에서 데이터가 실제/합성 결정 척도 활용 | |
| 성능 비교 측면 | 예측 정확도 확인 | 실제/합성 데이터 예측 분석 성능 비교, 모방 가능성 확인 |
| AUROC 측정 | 다양한 임계값에서 합성/실제 데이터 세트 분류 성능 측정 | |
| 데이터 간 관계 활용 측면 | 헬링거 거리 측정 | 실제 데이터 세트와 합성 데이터 세트 사이의 거리 측정 |
| 이변량 상관관계 | 서로 다른 두 변수 간 관계 확인 |
- 앞으로 합성 데이터가 인공지능 학습용 데이터의 대부분을 차지할 것으로 예상되며, 다양한 산업 및 업무 현장에서 학습, 연구 및 테스트 목적으로 합성 데이터 활용
3. 합성 데이터의 활용 분야
(1) 산업 활용 측면 합성 데이터 활용 분야
| 활용 분야 | 세부 활용 분야 | 활용 사례 및 효과 |
|---|---|---|
| 의료 산업 | 환자 기밀 유지 의료 연구/테스트 | – 환자 기밀 유지하면서 기록 데이터의 내/외부 사용 – 실제 의료 데이터 미존재 시 연구/테스트 목적 사용 |
| 보험 산업 | 리스크 관리 기반 보험 서비스 개선 | – 청구 데이터, 판매, 시장/설문 조사에 합성 데이터 사용 – 고객 여정 개선, 리스크 관리, 언더라이팅 정확도 향상 |
| 금융 산업 | 프라이버시 보호 사기탐지 고도화 등 | – 데이터 프라이버시 보호, 사기탐지 테스트 및 효과 평가 – 금융 고객 행동 이해 위해 합성 고객 거래 데이터 사용 |
(2) 업무현장 활용 측면 합성 데이터 활용 분야
| 활용 분야 | 세부 활용 분야 | 활용 사례 및 효과 |
|---|---|---|
| 머신러닝 | 머신러닝 기술 평가 및 비교 | – 비용 수반 없이 빅데이터 생성, 학습, 검증, 테스트 – 실제 데이터의 수집과 라벨링 소요 시간/비용 절감 |
| 프라이버시 공격 방어 | – 데이터 세트 내 과소 표현 모집단 강화 시 활용 – 탐색 강화, 학습, 검증, 테스트, 프라이버시 위험 완화 | |
| 교육/ 테스트 | 내부 소프트웨어 테스트 | – sub-standard 데이터 기반 불량률 감소, 신뢰성 테스트 – 개인 데이터 없이 개별 고객/환자 수준 데이터 테스트 |
| 교육, 훈련, 해커톤 | – 개인 데이터 처리 시 개인 정보 접속 없이 효과적 교육 – 인재 유지, 교육, 개발, 문제 해결에 유용 | |
| 조직 외부 공유 | 규제 문제 완화 | – 특정용도 개인데이터의 타 목적 사용 규제 문제 완화 – 개인 데이터 처리에 있어 법적 문제 해결 사례로 기록 |
| 데이터 접근성 강화 | – 개인정보 비식별화 불필요, 신속한 데이터 공유 가능 – 정확성, 완전성 등 고품질 데이터 확보 |
- 합성 데이터는 프라이버시 이슈에서 자유로운 많은 양의 데이터를 효율적으로 생성 가능하게 하며, 인공지능 모델 성능을 향상하는 데에 기여
- 그러나 합성 데이터에도 데이터 생성 방법 결정에 대한 전문성이 요구되며, 프라이버시 이슈, 데이터 편향에서 완전히 자유롭지 못하다는 점에서 신중한 접근이 필요
4. 합성 데이터의 한계점 및 극복 방안
| 구분 | 한계점 | 극복 방안 |
|---|---|---|
| 시간 및 숙련성 필요 | – 합성 데이터 생성 방법 개발 및 적용 시 많은 시간과 노력 소요 | – 다양한 데이터 생성 방법 개발 시도 – 유사 업무에 합성 데이터 활용 |
| 프라이버시 이슈 해소 노력 필요 | – 민감한 개인 정보 재식별 가능성이 감소하지만 여전히 이슈 | – 개인 재식별 방지위해 비즈니스 프로세스, 개인정보 규정 숙련 전문가 필요 |
| 데이터 편향 해소 노력 필 | – 기초 데이터에 숨겨진 편향을 그대로 반영할 위험 존재 | – 합성/원래 데이터 세트 간 유사성을 지속 모니터링, 데이터 유용성 확보 |
- 합성 데이터는 개인 정보 보호 문제를 줄이면서 적은 노력과 비용으로 무제한 데이터를 생성할 수 있다는 장점을 가지고 중요한 인공지능 학습 데이터로 부상하고 있음
- 합성 데이터를 활용하기 위해 여전히 고려할 이슈가 존재하므로 데이터 유용성 모니터링, 데이터 전문가 참여 등 지속적인 노력 필요
[참고]
- 정보통신정책연구원(KISDI), 합성 데이터(Synthetic data)의 부상
- 한국신용정보원, 합성데이터(Synthetic Data)를 통한 금용 AI 활성화 방안