2024년 11월 10일
데이터 전처리 (Data Preprocessing)
1. 데이터 전처리 (Data Preprocessing)의 개념
 | |
| 개념 | 데이터의 정합성과 가치 확보 위해 정제, 통합, 변환 등의 과정을 통해 데이터 분석 및 처리에 적합하도록 데이터를 조작하는 과정 |
|---|---|
- 완벽한 데이터 획득은 실제로 불가능하며, GIGO 이론에 따라 고품질의 데이터 분석을 위해서는 데이터 측정/수집 과정에서 발생한 오류에 대해 중복 제어, 모순/불일치 해소, 결측치/이상치를 처리하여 분석에 용이한 형태로 변환하여 제공하는 과정이 필수적으로 수반됨.
- GIGO(Garbage-In Garbage-Out): 쓰레기를 넣으면 쓰레기가 나온다.
2. 데이터 전처리 절차 및 주요 기법
(1) 데이터 전처리 수행 절차
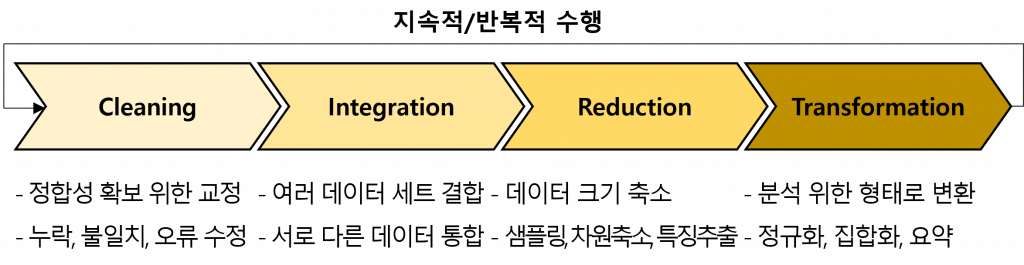 |
(2) 단계 별 주요 기법
| 단계 | 주요 기법 | 역할 / 세부 기법 |
|---|---|---|
| 정제 (Cleaning) | 결측값 (Missing value) 처리 | – 결측값 제거(개체/속성), 입력(수동, 전역 상수) – 결측값추정(회귀분석,베이지안,의사결정트리) |
| 잡음 (Noise) 제거 | – 오류/오차로 인한 경향성 훼손 방지 – 데이터 평활화(구간화, 회귀, 군집화) | |
| 통합 (Integration) | 개체 (Entity) 식별 | – 서로 다른 데이터 집합의 개체 식별 – 함수적 종속성, 메타데이터 활용 |
| 중복 제거 / 이상 해소 | – 데이터 중복에 따른 공간 낭비/이상 발생 해소 – 정규화/반정규화, 유도 속성, 상관 분석 | |
| 축소 (Reduction) | 데이터 큐브 (Data Cube) | – 다차원 집계 정보 추상화로 데이터 축소 – 데이터 큐브 슬라이싱, 큐브 격자 |
| 속성 부분집합 선택 (Attribute Subset Selection) | – 연관성이 낮거나 중복된 속성을 제거 – 의사결정 트리, 엔트로피, 지니 계수, 가지치기 | |
| 차원 축소 (Dimensionality Reduction) | – 원천 데이터 부호화 및 압축 – 웨이블릿 변환, PCA, DWT, 회귀/로그선형 모형 | |
| 수량 축소 | – 표본 추출(데이터 샘플 부분집합 표현) – 히스토그램 구간화, 군집화(그룹화) | |
| 변환 (Transfor -mation) | 정규화 (Normalization) | – 데이터세트 범위의 차이를 공통 척도로 변경 – 최소-최대 및 Z-score 정규화, 소수 척도화 |
| 수치 데이터 이산화 | – 엔트로피 기반 클래스 분포 계층적 이산화 – 카이제곱 x2 결합, 직관적 분할 이산화 | |
| 집합화 (Aggregation) | – 범주형 데이터 계층 생성 – 스키마 단계 생성, 명시적 그룹화 |
- 데이터는 사용하려는 목적에 맞는 품질을 확보해야 하므로 완전성, 정밀성, 일관성 등 데이터 속성을 고려한 전처리 수행 필요
3. 데이터 전처리 시 데이터 품질 속성 고려사항
| 데이터 품질 속성 | 고려사항 |
|---|---|
| 정밀성 (accuracy) | – 오류나 예상치에서 벗어나지 않도록 처리 |
| 완전성 (completeness) | – 속성 값이나 관심 속성이 모두 존재하도록 확보 |
| 일관성 (consistency) | – 데이터 값에 모순점이 없고 일관성을 확보 |
| 적시성 (timeliness) | – 필요한 시점에서 사용 가능한 상태로 제공 |
| 신빙성 (believability) | – 자료에 대한 신뢰도 확보 |
| 해석성 (interpretability) | – 데이터를 이해하기 쉽도록 처리 |
- 데이터 분석 부터 생성형 AI 모델 훈련 및 서비스까지 데이터 전처리는 다양한 데이터 활용 업무에 필수적인 과정이므로 효과적인 데이터 전처리를 위한 노력 및 연구 필요
[참고]
- 카오스북, Python과 SQL을 활용한 실전 데이터 전처리
- DIGITALSHIP, 데이터 전처리 기법 및 도구 소개
- PGWiki, 데이터 마이닝 개념과 기법/데이터 전처리