2025년 12월 7일
중첩 학습 (NL, Nested Learning)
1. 딥러닝 망각 문제 극복, 중첩 학습의 개요
- 중첩 학습 (NL, Nested Learning)
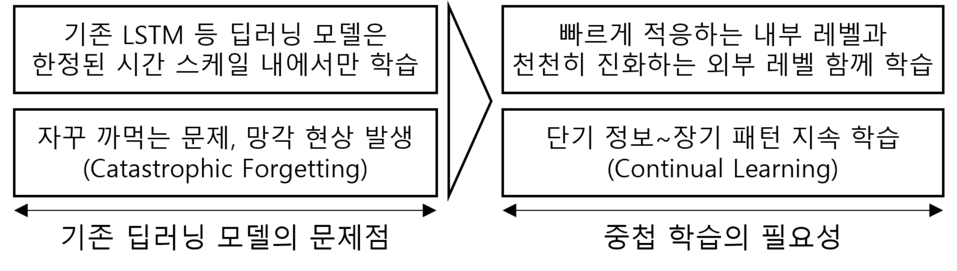
(1) 기존 딥러닝 모델의 문제점과 중첩 학습의 필요성
 |
(2) 중첩 학습의 개념 및 특징
| 개념 | 특징 |
|---|---|
| 기존 딥러닝 모델의 망각 문제 극복 위해 계층적/연관 기억, CMS, HOPE 아키텍처 기반 지속 학습을 제공하는 인공지능 학습 패러다임 | – 기존 학습 모델의 망각 문제 극복 – 불완전 데이터 지속적 적응력 향상 – 장/단기 기억을 다른 속도로 처리 – 장기적 복잡한 데이터 처리 개선 |
- 구글 연구진이 2025년 NeurIPS 학회에서 발표한 논문 “Nested Learning: The Illusion of Deep Learning Architectures”에서 처음 제안
- 딥러닝 모델을 하나의 단일 최적화 문제로 보는 기존 관점에서 벗어나, 여러 중첩, 다단계, 병렬적 최적화 문제 집합으로 모델을 표현하는 새로운 패러다임을 제시
- 인간 두뇌처럼 여러 학습 속도를 가진 계층들을 도입해 AI의 지속적 학습 능력을 높이는 것이 핵심
2. 중첩 학습의 메커니즘 및 핵심 기술
(1) 중첩 학습의 메커니즘
| 하이브리드 아키텍처 | 신경망 학습 모듈 |
|---|---|
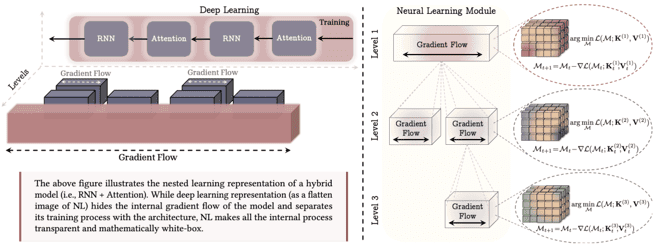 | |
| – 딥러닝은 블록 내 계산 깊이에 대한 통찰력 미제공 – 자연어 처리는 모든 내부 그래디언트 흐름 표현 | – 자체 컨텍스트 압축 방법 학습 계산 모델 – 첫 번째 레벨은 모델의 가장 바깥쪽 루프 학습에 해당(사전 학습 단계) |
(2) 중첩 학습의 핵심 기술
| 구분 | 핵심 기술 | 역할 |
|---|---|---|
| 구조/표현 관점 | 계층적 다중 최적화 | – 모델을 서로 다른 속도·규칙의 다층 최적화 문제로 설계 – 각 층이 고유한 컨텍스트 흐름과 업데이트 주기 보유 |
| 연관 기억 기반 표현 | – 역전파, 어텐션 등 모델 내부를 공통 메모리 구조로 통일 – 다양한 시간 기억(단/중/장기)을 한 프레임 안에서 구현 | |
| 메모리/ 시간 척도 관점 | 연속 메모리 (CMS) | – Continuum memory systems – 트랜스포머의 짧은 컨텍스트 + FFN 장기 기억 확장 – 여러 레벨로 나뉜 메모리 블록들이 서로 다른 빈도로 갱신 |
| 연속 학습/망각 완화 프레임 | – 새 과제 학습 시 기존 지식의 성능 저하를 줄이도록 설계 – 내부 시간·속도 계층 설계만으로 장기적인 연속 학습 지향 | |
| 학습 규칙/ 아키텍처 관점 | 딥 옵티마이저 (Deep Optimizers) | – 옵티마이저를 신경망으로 압축·저장 학습 모듈로 설계 – 같은 데이터에서 효율적 수렴, 연속 학습 안정적 적응 |
| HOPE 아키텍처 (자가 수정 아키텍처) | – Hybrid Optimization and Plasticity Engine – 여러 빈도 FFN/메모리 블록 자기 수정 시퀀스 모델 |
- 중첩 학습은 기존 딥러닝 모델과 달리 연속 학습이 가능하나, 아직 성능/검증 측면에 한계가 있어 연속 학습 검증 및 사례 연구 확대 필요
3. 중첩 학습의 한계점 및 고려사항
(1) 중첩 학습의 한계점
| 구분 | 한계점 | 제약 사항 |
|---|---|---|
| 설계 및 이론 측면 한계 | 구조 복잡도와 튜닝 난이도 | – 여러 레벨 옵티마이저/업데이트/메모리 계층 설계 필요 – 트랜스포머보다 구조 복잡, 큰 하이퍼파라미터 공간 필요 |
| 이론/표준 부재 | – 최적 레벨, 업데이트 빈도/용량 등 가이드와 표준 부족 – 현재는 사람의 설계 감각과 실험에 의존 | |
| 성능 및 검증 측면 한계 | 성능 개선 폭과 범위 불명확 | – 일부 벤치마크 외 비교 대상과 조건이 제한적 – LLM 전체를 대체할 수준의 우월성 입증 안됨 |
| 연속 학습 검증 부족 | – 논문이나 데모는 기존 모델 대비 망각 완화 강조 – 장기간/대규모 온라인 학습 시나리오 평가 부족 | |
| 인프라 측면 한계 | 계산/메모리 비용 증가 가능성 | – 여러 계층 상태와 다른 속도 업데이트 유지 필요 – 단순 트랜스포머보다 학습 및 추론 비용 증가 |
| 생태계/인프라 미성숙 | – 현재 H/W, S/W 스택은 트랜스포머 중심 최적화 – 프레임워크/가속기 등 인프라 변경 필요(도입 장벽) |
(2) 중첩 학습의 한계점 극복을 위한 고려사항
| 구분 | 고려사항 | 세부 목표 |
|---|---|---|
| 설계 및 이론 측면 한계 | 설계와 이론적 가이드 강화 | – 자동화된 하이퍼파라미터, 메타러닝 기반 설계 도구 개발 – 최적 레벨 수와 시간 척도를 수학적으로 모델링 및 표준화 |
| 성능 및 검증 측면 한계 | 확장성과 성능 검증 | – 다양한 대규모 벤치마크와 실제 연속 학습 시나리오 적용 – 산업 규모 LLM이나 챗봇에 장기 운용 및 망각 감소 실증 |
| 인프라 측면 한계 | 효율적 자원 관리 | – 경량화 및 저비용 변형 모델 연구, 대규모 스케일 대응 – NL 특화 하드웨어 가속기 및 통합 프레임워크 개발 |
- 중첩 학습은 향후 Gemini 4, 5 등의 차세대 AI에 통합 및 상용화될 가능성이 크며, 자체 개선(Self-Improving) 가능한 AI 개발의 토대로 자리잡을 것으로 전망
[참고]
- Google, Introducing Nested Learning, 2025.11
- Google Research, NeurIPS, Nested Learning: The Illusion of Deep Learning Architectures, 2025.11