2025년 12월 14일
HBF (High Bandwidth Flash)
1. 비휘발성 HBM, HBF (High Bandwidth Flash)의 개요
| 개념 | 특징 |
|---|---|
| HBM 용량 및 휘발성 한계 극복 위해 3D 스택형 낸드플래시를 TSV, 로직 다이, CBA 기반 병렬 연결하는 고대역폭 비휘발성 메모리 기술 | – 고대역폭 낸드플래시 – HBM 대비 초대용량 – AI 추론 특화 메모리 – 비휘발성 고속 백엔드 |
- 낸드 특성상 DRAM/HBM 대비 8~16배 이상 큰 용량을 비슷한 비용 수준에서 제공하는 것을 목표로 하며, 1세대 기준 GPU당 최대 4TB 수준의 VRAM 구성 가능
2. HBF의 구성도 및 핵심 기술
(1) HBF의 구성도
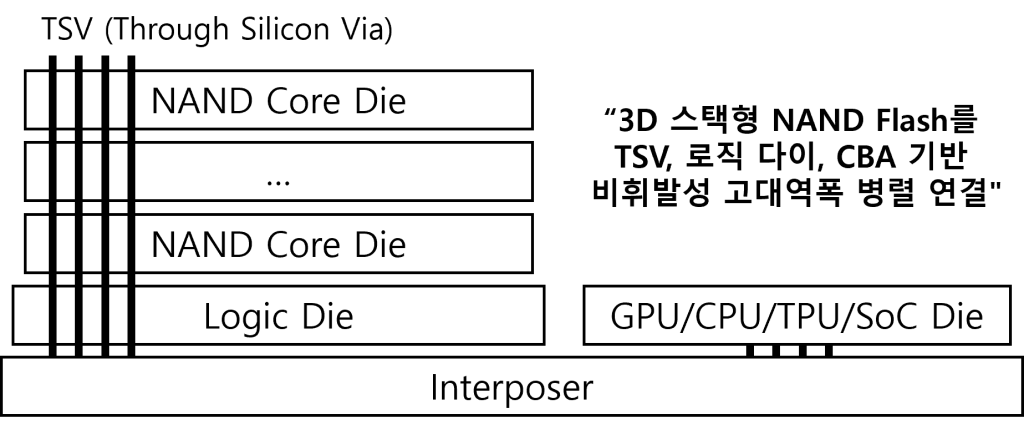 |
(2) HBF의 핵심 기술
| 구분 | 핵심 기술 | 역할 |
|---|---|---|
| 적층 구조 연결 측면 | 3D 스택형 낸드플래시 | – 여러 3D 낸드 다이 세로로 쌓아 하나의 패키지화 – 단일 패키지에서 매우 큰 용량(수 TB급까지) 확보 |
| TSV (Through- Silicon Via) | – 각 낸드 다이를 실리콘 관통전극으로 수직 연결 – 층마다 I/O 채널을 병렬로 묶어 대역폭 확대 | |
| 병렬 처리 효율화 측면 | 로직 다이 (Logic Layer) | – 스택 최하단 Layer로 컨트롤러 및 I/O 허브 역할 – 여러 낸드 서브어레이에 동시 접근 병렬 처리 |
| CBA (CMOS bonded to Array) | – 메모리셀 배열과 주변부 회로(CMOS) 직접 결합 – 하이퍼 본딩 기반 집적도 및 성능 향상 | |
| 서브어레이 연결 측면 | 다중 서브어레이 접근 | – 블록/페이지 분할 및 다수 서브어레이 동시 액세스 – 읽기 대역폭 극대화로 읽기 기준 HBM 수준 달성 |
| 인터포저 직접 접속 | – 실리콘 인터포저 기반 GPU 근접 배치 및 탑재 – PCIe/SSD 대비 고대역폭 메모리 버스 직접 연결 |
- HBF는 HBM/DRAM 대비 속도는 느리지만, 읽기 중심·고스루풋 워크로드(AI 추론, 대규모 임베딩 테이블 등)에 맞춰 전력당 처리량을 극대화하도록 설계
3. HBM과 HBF의 비교
| 비교 항목 | HBM | HBF |
|---|---|---|
| 기반 기술 | DRAM 기반 3D 스택 메모리, TSV·인터포저 구조 사용 | NAND 플래시 기반 3D 스택, TSV·CBA로 병렬 읽기 최적화 |
| 저장 용량 | 패키지당 수십 GB 수준 상대적으로 제한적 | HBM 대비 8~16배 이상, 패키지당 TB급까지 확장 가능 |
| 대역폭/ 지연 시간 | 매우 높은 대역폭과 ns급 초저지연 제공, 연산 캐시 용도 | 읽기 대역폭은 HBM에 근접 지연 시간은 µs 수준으로 높음 |
| 전력 효율 | 고대역폭 대비 전력 효율은 우수하나 가격이 매우 높음 | 전력당 처리량과 GB당 비용이 훨씬 유리, 유사 비용에 더 큰 용량 |
| 활용 | GPU 인접 연산용 고속 메인 메모리/캐시(학습, 실시간 연산) | 대용량 AI 모델 가중치 저장용 확장 VRAM/추론 특화 백엔드 |
- HBM이 초저지연/고속 캐시 역할, HBF가 대용량 메모리 계층을 담당하는 상호보완적 구조를 통해 LLM·멀티모달 AI 추론에서 모델 파라미터 전체를 GPU 인접 메모리에 상주시켜 추론 성능 극대화 가능
[참고]
- SANDISK, THE FUTURE OF MEMORY ARCHITECTURE FOR AI INTRODUCING: HIGH BANDWIDTH FLASH, 2025.7