2018년 12월 28일
K-means 알고리즘
1. Clustering을 통한 데이터 분류 기법, K-means 알고리즘
(1) K-means 알고리즘의 개념
- 데이터를 임의의 중심점을 기준으로 최소의 거리가 되도록 K개의 군집화 하여 분류하는 비지도 학습
(2) K-means 알고리즘 특징
| 반복적 | – 초기 잘못된 병합을 알고리즘 반복 수행 회복 |
| 대규모 적용 | – 간단하고 대규모 적용에 계산 시간 짧음 |
| 연관성 | – 연관성 높은 데이터는 근거리 위치 특성 이용 |
2. K-means 알고리즘 수행 절차
| 수행 절차 | 절차도 | 설명 |
|---|---|---|
| 1단계 초기설정 | 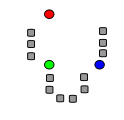 | – 클러스터 개수 결정(K = n) – 임의 Code-Vector n개 설정 – 각 CV 임의 좌표로 설정 |
| 2단계 군집분류 |  | – 각 데이터 유클리드 거리 계산 – 가장 가까운 중심을 해당 데이터의 대표로 설정 |
| 3단계 Code-Vector 갱신 |  | – 군집 학습 데이터 좌표 계산 – 각 데이터 좌표들의 평균을 새로운 중심으로 갱신, 이동 |
| 4단계 검증 및 완료 | 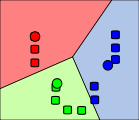 | – 보정 후 ② ~ ③ 단계 반복 – 더 이상 군집 데이터 변경이 없으면 학습 완료 |
- K-means 알고리즘은 노이즈에 민감하여 군집과 동떨어진 좌표가 중심이 될 수 있어 해결방안 필요
3. K-means 알고리즘의 문제점 및 해결방안
| 문제점 | 해결 방안 |
|---|---|
| – 오목한 군집 형태 시 문제 – 동떨어져 있는 데이터나 노이즈(noise)에 매우 민감 – 초기 중심 설정 방법 문제 | – K-medoids 기법 활용 – 노이즈 처리가 매우 우수 – 군집의 새로운 중심을 데이터 중 하나로 선정 |