2019년 1월 4일
KNN (K-Nearest Neighbor)
1. 확률 밀도 추정 알고리즘, KNN (K-Nearest Neighbor)
(1) KNN의 개념
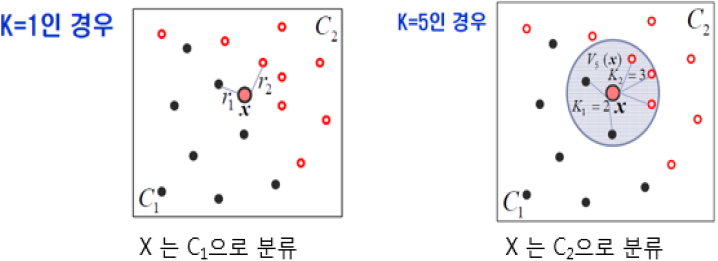 |
- Sample에 주어진 x에서 가장 가까운 k개의 원소가 많이 속하는class로 x를 분류하는 비모수적 확률밀도 추정방법
(2) KNN 특징
| NN 개선 | – k개의 데이터에 대한 다수결 방식 |
| 인스턴스 개선 | – 함수의 지역적 근사에 기반한 추정 |
| 게으른 학습 (Lazy Learning) | – 데이터셋 저장만 하며, 일반화된 모델을 능동적으로 만들지 않음 |
- 기존 데이터에서 유사 데이터 k개 찾아, 그 데이터의 평균을 예측값으로 사용
2. KNN 동작 원리
| 동작 원리 | 설명 |
|---|---|
| Fingerprint DB 구축 | – 특정 위치를 참조 위치로 지정, 해당 지점에서 측정 이동 객체 신호 강도 DB화 |
| 데이터셋 그룹핑 | – Fingerprint DB 내 데이터 표준 그룹화 – 데이터가 일정한 기준에서 활용, 재조정 |
| 거리측정 | – 유클리드 거리 측정 |
| 매개변수 선택 (k값 선정) | – 데이터 분류 통해 최적 성능 k값 선택 – 작은 k값은 Overfitting 가능성 높음 – 큰 k값은 Underfitting 가능성 높음 |
| 후보집합 생성 | – 최소 거리부터 순서대로 k개 데이터 찾아 후보 집합 생성 및 정렬 – 후보 집합: N(x) = {x1, x2, … , xk} |
| Label 값 확인 | – 후보 집합의 각 원소가 어떤 클래스에 속하는지 Label 값 확인 – Label 값: y(x1), y(x2), … , y(xk) |
| 클래스 맵핑 | – 확인한 Label값 중 가장 많은 빈도 수 차지 클래스 찾아 x를 클래스에 맵핑 |
- KNN의 성능은 1)k값 최적화, 2)Underfitting, Overfitting의 적절한 고려가 필요
3. KNN의 장/단점
| 구분 | 설명 | |
|---|---|---|
| 장점 | 효율성 | – 훈련 데이터에 잡음 있어도 적용 가능 |
| 결과 일관성 | – 데이터 수가 증가해도 오차율 낮음 – 임의의 k값에 대해 베이즈 오차율 근접 | |
| 단점 | 성능 가변성 | – k값 선정에 따라 알고리즘 성능이 좌우 – k값 최적화, Under/Overfitting 고려 필요 |
| 높은 자원 요구량 | – 데이터셋 전체 읽어서 메모리에 기억 – 신규 객체 읽어 메모리 데이터셋 비교 | |
| 고비용 | – 모든 훈련 샘플과 거리를 계산해야 하므로 연산 비용(cost) 높음 | |
- KNN의 단점 보완 위해 타 알고리즘과 병행하거나, 훈련데이터셋을 크게 하는 KD트리 활용 방법으로 보완
4. KNN의 활용 방안
| 동작 원리 | 설명 | 사례 |
|---|---|---|
| 위치 측위 | – 이동 객체의 위치에서 AP 신호 강도 측정하여 이동 객체 위치 최종 추정 | – MS RADAR – Wi-Fi RTLS, COMPAS |
| 선호도 분류 | – 사용자 추천정보 기반 성향/구매 패턴 분류 | – 내용기반 추천시스템 |
| 데이터 필터링 | – 포털 등의 중복, 유사 게시글 필터링 | – 문서 분류 빈발 단어 |
| 고속도로 통행시간 예측 | – TCS교통량 및 DSRC통행시간 – 실시간 자료 KNN 기반 분석 | – 차량근거리 무선통신 |