2019년 1월 22일
Q-러닝 (Q-Learning)
I. 강화 학습 기법, Q-러닝(Q-Learning)
- 특정 상태에서 행동에 대한 미래값(Q)을 계산하여, 최적 정책을 찾는 마르코프 의사결정 기반 강화학습 기법
- 마르코프 의사결정 : 다음 상태의 확률은 오직 현재 상태와 행동에만 영향을 받고, 이전 상태에서 영향 받지 않는 의사결정
II. Q-러닝 학습 절차 및 구성요소
가. Q-러닝의 학습 절차
| 학습 절차 | 설명 |
|---|---|
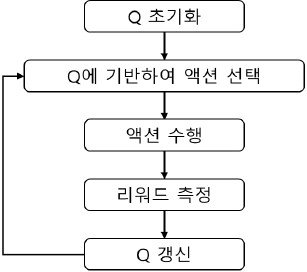 | ① value table Q 초기화 ② 정책 기반 Action 선택/수행 ③ 새로운 상태 및 보상 관찰 ④ 다음상태 최대보상 업데이트 ⑤ 새로운 상태 설정, 반복수행 |
- 보상에 의한 정책에 따라 액션 수행, 보상 측정/업데이트 수행
나. Q-러닝의 구성요소
| 구분 | 구성요소 | 설명 |
|---|---|---|
| 정책 (Policy) | – 최대 보상 – 미래보상 관찰 | – 최고 Q값 기반 액션 선택 – π(s)=argmax Q(s,a) |
| 벨만 방정식 | – 정책 반복 – 재귀함수 | – 최적정책 찾는 반복수행 – 현재 최고보상, 미래보상 |
| Q-러닝 알고리즘 | – 테이블 기반 – 반복적 근사 | – 벨만 방정식 반복 수행 – 반복 기반 Q함수 근사 |
- 테이블 형태의 Q-러닝 알고리즘 사이즈 문제에 대한 해결방안으로 DQN 등장
III. Q-러닝 사이즈 문제 해결 위한 DQN(Deep Q Network)
| 구분 | 구성요소 | 설명 |
|---|---|---|
| ConvNet 활용 | 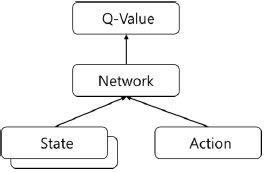 | – 상태와 액션 입력 받아 상태와 액션의 Q함수값 출력 |
| Feed Forward 수행 | 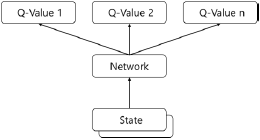 | – 상태값만 입력받아 피드포워드 과정 – 각 액션 별 Q함수값을 한번에 출력 |
- 신경망에서 손실함수(loss function)은 제곱오차로 정의 가능, 테이블 형태의 Q-러닝 함수 오차정의와 유사