2018년 12월 19일
Word2Vec
1. word embedding 성능 향상, Word2Vec
(1) Word2Vec의 개념
- 단어를 벡터 평면에 배치하여 컴퓨터가 인식할 수 있도록 문맥적 의미를 보존하는 워드임베딩 기법
- 출력 스코어에 Softmax 적용하여 정답과 비교해 역전파 수행
2. Word2Vec 신경망 연산 기법 및 학습 모델
(1) Word2Vec의 신경망 연산 기법
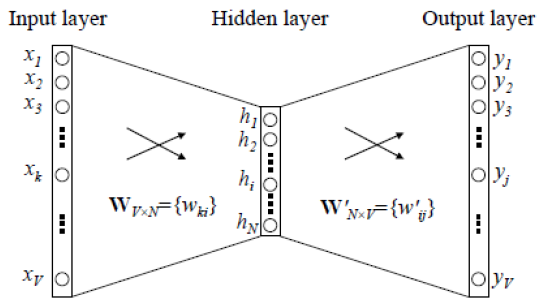 |
| – 은닉 벡터(h) = 입력(x) x 입력 가중치 행렬(W) – 출력(y) = 은닉 벡터(h) x 출력 가중치 행렬(W’) |
(2) Word2Vec의 학습 모델
| 모델 | 개념도 | 프로세스 |
|---|---|---|
| CBOW | 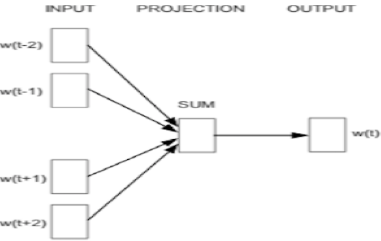 | ① One-Hot Encoding 삽입 ② Projection벡터평균적용 ③ Matrix 연산후 출력전송 ④ Softmax 계산, 단어비교 |
| Skip- gram | 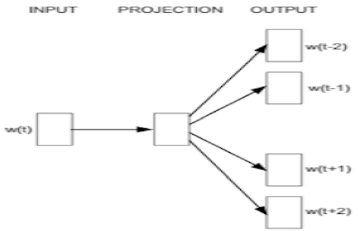 | ① One-Hot Encoding 삽입 ② Projection요소 1:1 대응 ③ Matrix 연산후 출력전송 ④ Softmax 계산, 단어비교 |
- Skip-gram은 말뭉치 내 존재 모든 단어를 학습하며, CBOW보다 학습 기회가 많아 일반적으로 사용
3. Word2Vec 성능 확보를 위한 기술
| 단어 빈도 기반 Subsampling | Negative Sampling |
|---|---|
| – 코퍼스빈출단어 학습량낮춤 – 업데이트 기회가 많은 단어의 학습량을 확률적 감소 | – 일부 단어 대상 확률 계산 – 지정 크기 내 미출현 단어 추출 후 전체 단어셋 구성 |
- 자연어처리 기술 중 학습속도와 성능이 우수하여 활용 증가
4. Word2Vec 기반 문서 간 유사도 측정 기법
(1) 문서 간 유사도 측정 절차도
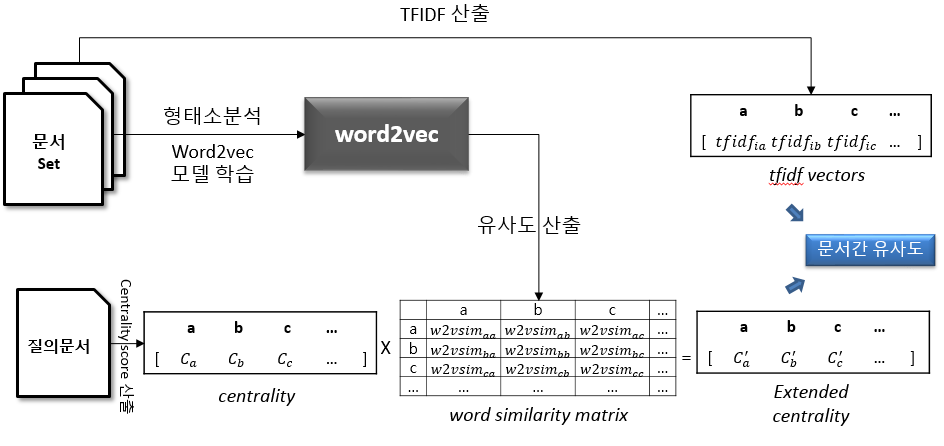 |
- 문서 포함 단어와 중요도를 벡터 공간 모델 형태로 저장, 문서 입력 및 변환하여 유사도 비교를 통해 추천
(2) 문서 간 유사도 측정 세부 절차 설명
| 구분 | 절차 | 설명 |
|---|---|---|
| 훈련 과정 | 쿼리문서 그래프 추출 | 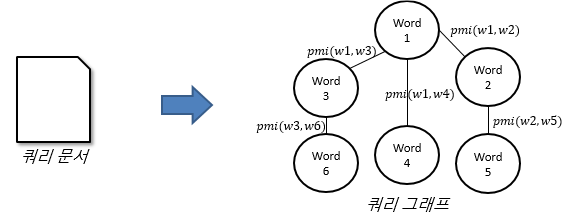 – PMI 지수 활용 노드 간 관계 표현 |
| 페이지랭크사용 단어 중요도 추출 | 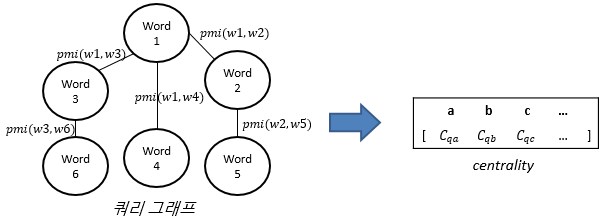 – 노드 내 숫자는 중요도를 의미 | |
| word2vec 모델링 | 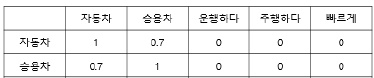 – 단어 간 유사도 행렬 사용 | |
| 비교 과정 | 단어 유사도 기반 쿼리확장 | 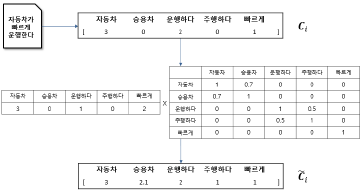 – 쿼리 확장 시 각 요소 중요도 평가 |
| 문서 간 비교 결론 출력 | 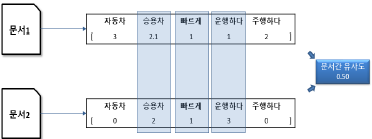 – 문서 셋 벡터 간 유사도 기준 추천 |
- 문서 훈련 및 비교를 통해 검색, NLP, 정보제공 분야에 활용
5. Word2Vec의 활용 분야
| 활용 분야 | 설명 |
|---|---|
| 지식, 검색, 정보제공, 챗봇 | – 유사어 학습을 통해 지식 정보 검색, Q&A, 챗봇을 활용한 무인 상담 등 |
| 음성 인식, NLP 가상비서, Zero UI | – 음성과 단어/문맥 연계로 의미 파악 – 대화 의미 분석을 통한 요구사항 수행 |
- 이 외 유사 상품 추천, 데이터 큐레이션 등 다방면에 활용 가능