2018년 12월 21일
기계 학습 (Machine Learning)
1. 인간의 학습 과정 모방, 기계 학습
| 개념 | 대량의 데이터를 지도/비지도, 강화 학습 등을 통해 문제의 해답을 찾아내는 기법 |
|---|
- 지도 학습(Supervised Learning), 비지도 학습(Unsupervised Learning), 강화 학습(Reinforcement Learning), 준지도 학습(Semi-Supervised Learning) 등이 포함
2. 기계 학습 중 지도 학습과 비지도 학습의 개념
| 지도 학습 | 비지도 학습 |
|---|---|
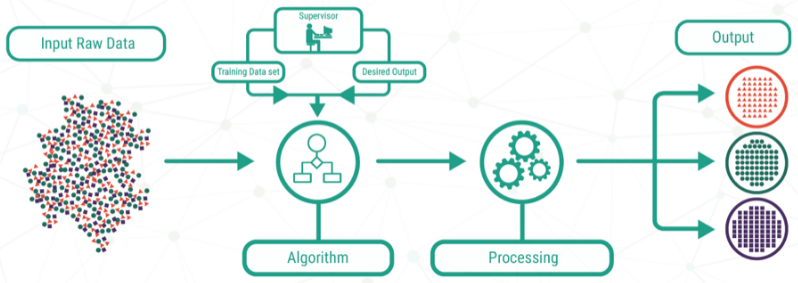 | 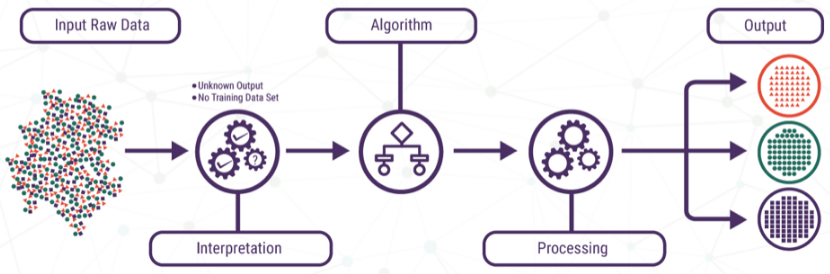 |
| – 입출력이 쌍으로 구성된 학습 예제로부터 맵핑하는 함수 학습 형태 | – 목표값 없이 입력값으로 공통 특성을 파악하는 귀납적 학습 형태 |
3. 지도 학습과 비지도 학습의 특징
| 구분 | 지도 학습 | 비지도 학습 |
|---|---|---|
| 사용이유 | – 예측 모델 생성 | – 고차원 데이터 분류 |
| 성능평가 | – 교차검증 수행 | – 검증 방법 없음 |
| 입력정보 | – Labeled Data | – Raw Data |
| 유형 | – 회귀: (x, y)로 f(x)=y파악 – 분류: 그룹별 특징 파악 | – 군집: 데이터끼리 묶음 – 패턴인식: 여러그룹인식 |
| 알고리즘 | – MLP, KNN, SVM, 의사결정 트리 등 | – K-Means, DBSCAN, DNN 등 |
| 장점 | – 사람이 목표 값에 개입하여 정확도가 높음 | – 목표 값을 정해주지 않아도 되므로 속도 빠름 |
| 단점 | – 시간이 오래 걸리고 학습 데이터 양이 많음 | – 학습 결과로 분류 기준과 군집 예측 불가 |
| 사례 | – 패턴, 질병진단 – 주가 예측, 회귀 분석 | – 스팸필터, 차원 축소 – 데이터마이닝, 지식발굴 |
- 지도/비지도 학습과 함께 환경으로부터 벌칙과 보상에 의한 학습 모델인 강화 학습이 대표적
3. 시행착오 기반 강화 학습 (Reinforcement Learning)
| 구분 | 설명 |
|---|---|
| 개념 | – 벌칙과 보상 기반 최적의 결정 방법을 학습 – 사람과 동물이 학습하는 원리를 실시간 적용 |
| 학습유형 | – 시행착오: 보상/벌칙 기억 최선의 결정 학습 – 최적제어: 시간 흐름에 따라 과정 별 최적 결정 |
| 알고리즘 | – Q-learning, DQN, Policy Gradient |
| 사례 | – 바둑(알파고), 게임, 로보틱스, 웹 정보 검색 |