2026년 1월 24일
네오클라우드 (Neocloud)
1. 네오클라우드 (Neocloud)의 개념 및 특징
(1) 네오클라우드의 개념
(2) 네오클라우드의 특징
| 분야 | 특징 | 세부 내용 |
|---|---|---|
| Compute | 베어메탈 기반의 GPU 리소스 극대화 | – Bare-Metal 또는 컨테이너 Pass-through를 채택하여, 고성능 GPU 연산 능력을 100% 활용 보장 |
| Network | RDMA 기반의 초저지연 네트워크 패브릭 | – RDMA 기술(InfiniBand, RoCE)을 적용하여, 노드 간 통신 지연 시간을 마이크로초(μs) 단위로 단축 |
| Storage | CPU를 우회하는 GPU Direct 스토리지 | – 스토리지 데이터가 GPU 메모리로 바로 적재(Direct Path) 되도록 경로 최적화, 데이터 로딩 속도 비약적 향상 |
| Architecture | 고밀도 집적 및 하이퍼스케일 클러스터링 | – GPU 노드가 물리적으로 가깝게 배치되어 하나의 거대한 컴퓨터처럼 유기적으로 동작하는 대규모 클러스터 구성 |
- 최근 IT 인프라 산업 동향으로, 폭발적인 AI 서비스 증가에 따라 요구되는 인프라는 웹 서비스 등 범용 목적의 CPU 중심 아키텍처에서 LLM 등 AI 학습/추론 목적의 GPU 중심 아키텍처로 변화중
2. 네오클라우드의 아키텍처 및 핵심 기술요소
(1) 네오클라우드의 컴퓨팅 아키텍처
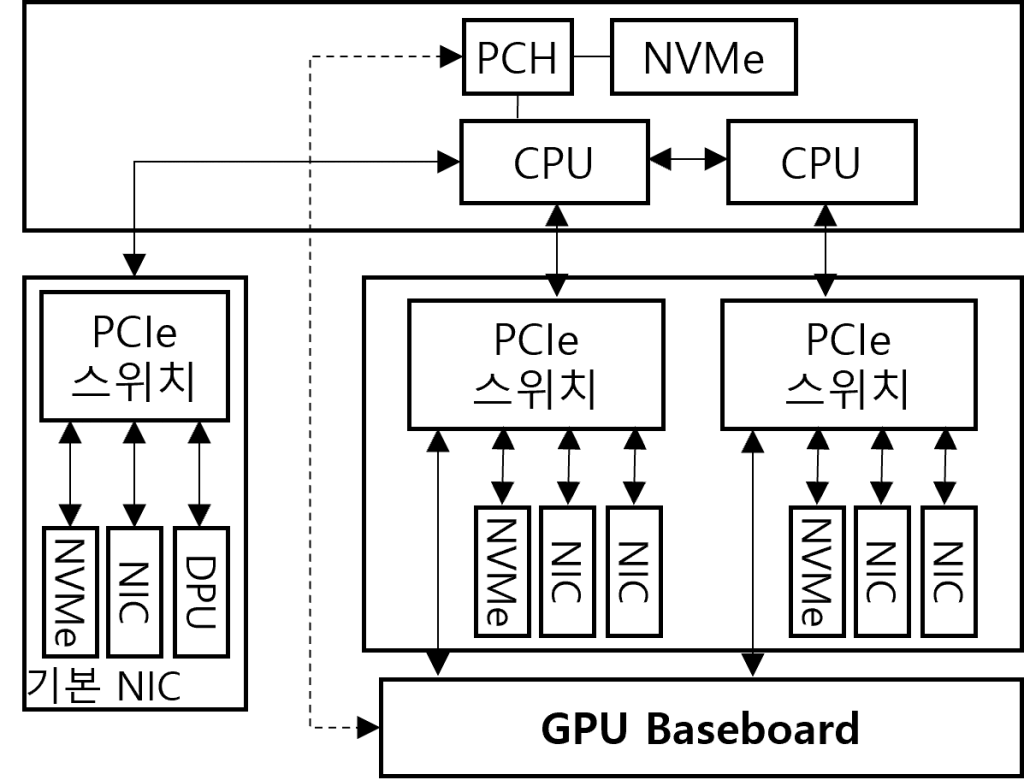 |
- GPU 간, GPU Direct 고속 통신에 RDMA, NVMe 기반 SSD, DPU 및 클라우드 기반 GPU 가상화로 구성
(2) 네오클라우드의 핵심 기술요소
| 구분 | 기술요소 | 역할 |
|---|---|---|
| 연산 능력 최적화 측면 | 베어메탈 컨테이너 (Bare-Metal Containerization) | – Hypervisor 제거, 컨테이너가 GPU에 직접 명령 – VM 방식의 Overhead 제거, 물리 서버 성능 확보 |
| MIG (Multi-Instance GPU) | – 물리적으로 분리된 여러 GPU 인스턴스로 분리 – 추론, 소규모 학습 시 비용 효율성 향상 | |
| GPU간 초고속 통신 측면 | RDMA (Remote Direct Memory Access) | – 데이터를 원격 노드 GPU 메모리로 직접 전송 – InfiniBand, RoCE |
| 레일 최적화 토폴로지 (Rail-Optimized Topology) | – 각 서버의 같은 위치 GPU는 단일 스위치로 통신 – 스위치 홉(Hop) 최소화, 데이터 충돌 차단 | |
| 대규모 데이터 접근 측면 | GDS (GPU Direct Storage) | – NVMe SSD 데이터를 GPU 메모리로 직접 전송 – DMA, 데이터 로딩 속도 비약적 향상 |
| 병렬 파일 시스템 (Parallel File System) | – 대규모 파일 시스템 동시 접근, PB급 대역폭 제공 – Lustre, GPFS, WEKA | |
| 구조 및 기반 시설 측면 | 스케일러블 유닛 (SU, Scalable Unit) | – GPU 서버와 스위치를 하나의 블록으로 규격화 – SU 단위 증설로 전력, 냉각, 성능 선형적 확장 |
| 데이터센터 액체 냉각 (Datacenter Liquid Cooling) | – 냉각된 액체를 순환시켜 고밀도 H/W 온도 제어 – 칩 직접 냉각(D2C), 액침 냉각, AALC |
- 네오클라우드 기업으로 AWS, Azure 등 글로벌 빅테크와 CoreWeave 등 AI 특화 클라우드 전문 기업이 있으며, 국내 클라우드 기업에서는 NPU(리벨리온, 사피온 등) 도입하여 서비스 제공중
3. 일반 클라우드와 네오클라우드 차이점
| 비교 항목 | 일반 클라우드 | 네오클라우드 |
|---|---|---|
| 핵심 워크로드 | 웹/앱 서비스, DB, 마이크로서비스 (일반적인 IT 서비스 운영) | LLM 학습, 대규모 추론, 3D 렌더링 (고성능 병렬 연산 처리) |
| 컴퓨팅 아키텍처 | CPU 중심 (Virtualization) 하이퍼바이저 기반 VM (오버헤드) | GPU 중심 (Bare-Metal) OS가 H/W 제어 (Overhead 최소화) |
| 리소스 할당 방식 | 멀티테넌트 (Multi-tenant) 물리 서버를 여러 사용자가 공유 | 단독 점유 (Single-tenant / Isolation) 고성능 유지 위해 물리 자원 독점 보장 |
| 네트워크 기술 | 이더넷 (Ethernet, TCP/IP) 연결성 중심, CPU가 통신 처리 | InfiniBand / RoCE (RDMA) 초저지연, GPU 메모리 간 직접 통신 |
| 트래픽 흐름 | North-South 중심 (서버 ↔ 외부 사용자 간 통신) | East-West 중심 (내부 GPU 노드 간 파라미터 교환) |
| 스토리지 경로 | Standard I/O스토리지 → RAM → CPU → GPU | GDS (GPU Direct Storage) 스토리지 → GPU (Direct Path) |
| 주요 병목 지점 | Disk I/O, 데이터베이스 | GPU 메모리 대역폭, 네트워크 지연(Latency) |
- 네오클라우드 시장 선도를 위해 구리선(Copper Cable)의 물리적 한계 해결을 위해 All-Optical Switch Fabric이 고려되어야 하며, Memory Wall 문제 해결을 위해 HBM, CXL 기반 Memory Pool 방식 사용, 효과적인 열 배출을 위한 액침 냉각에 대한 연구/개발 필요
[참고]
- Mckinsey & Company, Po Massimo Mazza, The evolution of neoclouds and their next moves, 2025.11
- Cisco, Jake Katz, Neocloud Providers Are Making Waves, 2025.12
- NVIDIA, DGX SuperPOD: Next Generation Scalable Infrastructure for AI Leadership, 2023.9
- SemiAnalysis, Dylan Patel and Daniel Nishball, AI Neocloud Playbook and Anatomy, 2024.10