2018년 12월 21일
데이터베이스 반정규화
1. 성능 향상을 위한 데이터 중복 허용, 데이터베이스 반정규화
| 개념 | 필요성 |
|---|---|
| 데이터베이스 정규화 후 성능향상, 개발편의성 등 위해 정규화를 의도적으로 위배하여 수행하는 기법 | – 다수 Join시 성능 하락 방지 – 개발 및 운영 단순화 – DB 검색 성능 향상 |
2. 데이터베이스 반정규화 필요 대상 및 유형
(1) 반정규화 필요 대상
| 구분 | 필요 대상 | 설명 |
|---|---|---|
| 접근빈도 측면 | 고빈도 테이블 | – 단일 테이블 다수 접근 |
| 다수 프로세스 | – 특정 프로세스 중심 | |
| 범위 측면 | 일정 범위 조회 | – 범위 한정 Select, Update |
| 통계성 작업 | – DW, OLAP 용 트랜잭션 | |
| 성능측면 | 다수 조인 | – 성능 하락 현상 발생 |
(2) 반정규화 유형
| 구분 | 유형 | 설명 |
|---|---|---|
| 테이블 분할 | 수평 분할 | – 레코드 단위로 분할 |
| 수직 분할 | – 컬럼 단위로 분할 | |
| 테이블 중복 | 통계 테이블 추가 | – DW, OLAP 데이터 용 |
| 진행 테이블 추가 | – 업무 프로세스 상태 | |
| 컬럼기반 분할 | 조회 빈도 기반 분할 | – 고빈도 컬럼 분리 |
| 크기 기반 분할 | – 일정 용량 컬럼 분리 | |
| 컬럼 중복 | 중복 컬럼 추가 | – 자주 조회되는 컬럼 추가 |
| 파생 컬럼 추가 | – 연산 결과 별도 저장 |
3. 반정규화 절차
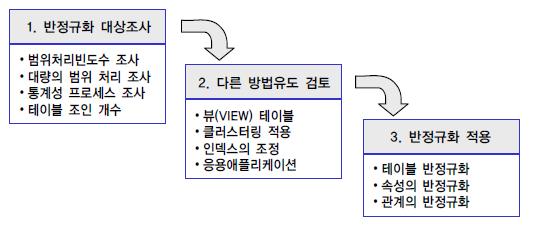
(1) 반정규화 절차
 |
(2) 반정규화 세부 절차
| 절차 | 방법 | 설명 |
|---|---|---|
| 반정규화 대상 조사 | – 범위 처리 빈도수 조사 | – 자주 사용되는 테이블에 접근 – 프로세스, 일정 범위만 조회 |
| – 통계성 프로세스조사 | – 통계 정보 필요시 별도 통계 테이블(반정규화 테이블) 생성 | |
| – 테이블조인 개수 조사 | – 많은 조인으로 인해 조회작업 – 기술적 어려움 시 반정규화 | |
| – 대량 범위 처리 | – 테이블에 대량 데이터 범위 – 자주 처리하는 경우 | |
| 다른방법 유도검토 | – 뷰(View) 테이블 | – 많은 조인으로 인해 조회작업 – 기술적 어려움 시 뷰 검토 |
| – 클러스터링 적용 | – 대량의 데이터를 클러스터링하여 저장(조회 중심) | |
| – 인덱스 적용 | – 인덱스 통해 성능 확보 가능시 인덱스 조정 | |
| – 응용 어플리케이션 | – 응용 어플리케이션에서 로직 구현 방법을 변경 | |
| 반정규화 적용 | – 테이블 반정규화 | – 테이블 단위 반정규화 – 테이블 병합, 분할, 추가 |
| – 속성 반정규화 | – 컬럼 단위 반정규화 – 중복, 파생 컬럼 추가 | |
| – 관계 반정규화 | – PK, FK 간 관계 반정규화 – 조회 관계 단순화, 중복 |
4. 반정규화 시 고려사항
- 정합성, 무결성 vs 성능, 테이블 단순화 Trade off
- 성능, 모델 단순화 이점, 무결성 저하로 시스템 안정성하락 우려로 정규화 완료 상태에서 수행
- 데이터 의미 변형/업무 규칙 감추어져서는 안됨
- 데이터 무결성 유지 방안 마련 후 적용
- 반정규화는 성능/관리 효율 증대, 데이터 일관성/정합성 위험 내포
About The Author
도리
One Comment
매번 잘 보고 갑니다. 설명을 이해하기 쉽게 잘 해주셔셔, 유튜브에서 동영상과 함께 자주 보고 있습니다. 감사합니다.