2020년 11월 9일
워드 임베딩(Word Embedding)
I. 기계의 자연어 처리를 위한 워드 임베딩의 필요성
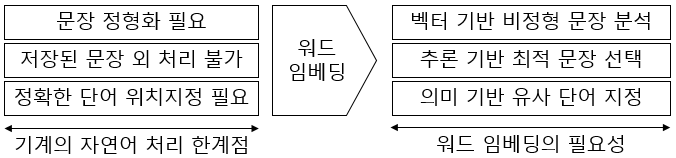 |
- 유사한 의미의 단어를 군집화하고 벡터 연산을 통해 단어 간의 관계를 파악하여 추론이 가능해짐에 따라 자연어 처리 모델링에 필수 기술로 사용
II. 단어의 벡터화, 워드 임베딩의 개념과 유형
가. 워드 임베딩의 개념
| 개념도 | 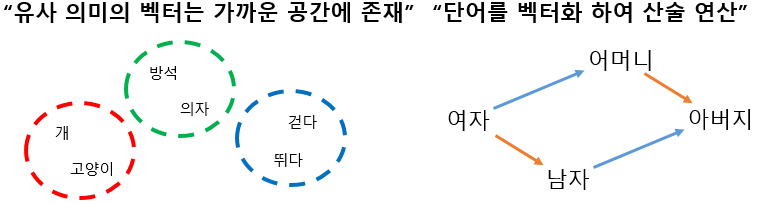 |
|---|---|
| 개념 | 단어 간 유사도 및 중요도 파악을 위해 단어를 저차원의 실수 벡터로 맵핑하여 의미적으로 비슷한 단어를 가깝게 배치하는 자연어 처리 모델링 기술 |
- 단어의 벡터화 방식은 희소표현(Sparse Representation) 방식과 밀집표현(Dense Representation) 방식이 있으며, One-Hot Encoding으로 대표되는 희소표현 방식 사용 시 단어 수 증가에 따라 벡터 차원이 무한정 커지는 공간적 낭비 해결을 위해 Word Embedding으로 대표되는 Dense Representation 방식 사용
나. Dense Representation Matrix, 워드 임베딩의 유형
| 구분 | 유형 | 원리 |
|---|---|---|
| 횟수 기반 임베딩 (Frequency Based Embedding) | BOW (Bag of Words) | – 단어의 출연 빈도만으로 단어 사전(주머니) 생성 – 각 단어 인덱싱 기반 사전으로 만들어 자동 분류 |
| Count Vector | – 모든 문서의 단어 학습 후 문서 마다 단어 횟수 파악 – 각 문서 별 고유 토큰 수 기반 행렬(Matrix)로 표현 | |
| TF-IDF | – 핵심어 추출 위해 단어의 특정 문서 내 중요도 산출 – TF: 단어의 문서내 빈도, IDF: 문서 빈도 수(DF)의 역수 | |
| 추론 기반 임베딩 (Prediction Based Embedding) | CBOW | – 주변 단어 기반 해당 위치에 나타날 수 있는 단어 추론 – 컨텍스트에서 단어의 평균을 적용하여 Softmax 계산 |
| Skip-gram | – 입력 단어를 통해 주변에 나타날 수 있는 단어를 추론 – 컨텍스트에서 단어를 1:1로 대응하여 Softmax 계산 | |
| Word2Vec | – 단어를 벡터 평면에 배치하여 문맥적 의미 보존 – 신경망 연산 수행하며 CBOW와 Skip-gram 모델 적용 |
- 횟수 기반 임베딩(Frequency Based Embedding)의 대표적 기법으로 TF-IDF를 사용하며, 추론 기반 임베딩 (Prediction Based Embedding)의 대표적 기법으로 CBOW와 Skip-gram방식을 적용한 Word2Vec을 사용
III. 워드 임베딩의 대표 기법, TF-IDF와 Word2Vec
가. Frequency Based Embedding, TF-IDF
| 구분 | 항목 | 상세 설명 |
|---|---|---|
| 개념 | TF-IDF | 핵심어 추출 및 검색 결과 순위 결정을 위해 단어의 특정 문서 내 중요도를 산출하는 통계적 가중치 알고리즘 |
| TF | 해당 단어의 문서 내 등장 빈도, 고빈도 출현 시 중요도 높음 | |
| IDF | 해당 단어가 출현하는 문서 빈도수(DF)의 역수, DF가 높을수록 흔한 단어로 판단 | |
| TF-IDF 단어 중요도 산출 기법 | TF 산출 | – 불린 빈도: 단어 등장 시 1, 아니면 0 – 로그스케일 빈도: TF값 발산 방지 – 증가 빈도: 문서 길이에 따라 단어 빈도 조절 – 증가 빈도 산출식: tf(t, d) = 0.5 + {0.5 x f(t, d)} / max{f(t’, d):t’ ∈ d} |
| IDF 산출 | – 역문서 빈도: log문서 크기 / 단어 t가 포함된 문서 – 역문서 빈도 산출식: idf(t, D) = log[|D| / {1 + (d ∈ D:t ∈ d)}] | |
| TF-IDF 산출 | – 단어 중요도는 TF에 비례, DF에 반비례하므로, TF x IDF 비례 – TF-IDF 산출식: tfidf(t, d, D) = tf(t ,d) x idf(t, D) |
- [산출 기법 범례] t : 단어, d : 문서, D : 문서의 크기(또는 전체 문서 수), f(t, d) : 단어 빈도 계산 함수
- TF-IDF의 단어 유사도 측정 기법으로 각도 기반 코사인 유사도, 평면 상 거리 계산 기반 유클리드 유사도, 대각선 없이 직각 거리 측정 기반 맨해튼 유사도 등 사용
나. Prediction Based Embedding, Word2Vec
| 구분 | 항목 | 상세 설명 | |
|---|---|---|---|
| 개념 | Word2Vec | 단어를 벡터 평면에 배치하여 컴퓨터가 인식할 수 있도록 문맥적 의미를 보존하는 워드 임베딩 기법 | |
| Word2Vec 신경망 연산 | 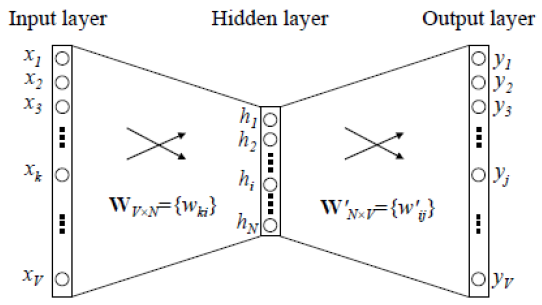 | ||
| Word2Vec 학습 모델 | CBOW | 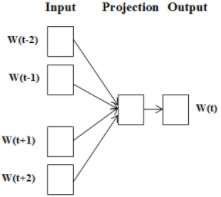 | ① One-Hot Encoding 방식 벡터화 ② Projection벡터들의 평균 적용 ③ Matrix 연산 후 출력 전송 ④ Softmax 계산, 단어 비교 |
| Skip-gram | 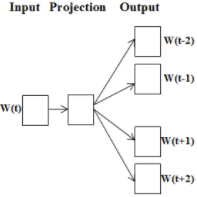 | ① One-Hot Encoding 방식 벡터화 ② Projection요소 1:1 대응 ③ Matrix 연산 후 출력 전송 ④ Softmax 계산, 단어 비교 | |
- Skip-gram은 말뭉치 내 존재 모든 단어 학습하며, CBOW보다 학습 기회가 많아 Skip-gram 다수 사용
IV. TF-IDF와 Word2Vec 기법 비교
| 비교 항목 | TF-IDF | Word2Vec |
|---|---|---|
| 임베딩 원리 | 횟수(Frequency) 기반 | 추론(Prediction) 기반 |
| 임베딩 방식 | TDM(Term-Document Matrix) 내 중요도 산출 | 단어를 벡터 평면에 배치 및 결과 추론 |
| 연산 대상 | 문서 내 단어 등장 횟수 연산 | 단어 벡터 간 연산 |
| 적용 모델 | TF, DF, IDF, TF x IDF | CBOW, Skip-gram |
| 활용 방안 | 검색 순위, 핵심 단어 추출 | 자연어 문장 생성 |
| 활용 서비스 | 검색 트렌드 분석, 유사도 비교 | 챗봇, 가상 비서 |
- 기계가 자연어 이해 기반 처리를 위해 자연어를 벡터화 하여 처리하며, 단어의 표현 방법에 따라 처리 성능이 크게 달라지므로 이에 대해 다수 연구 진행
- 문서의 통계 정보 반영 개선 및 임베딩된 단어 벡터 간 유사도 측정 개선을 통해 횟수 기반과 추론 기반 임베딩을 모두 사용하는 GloVe(Global Vectors for Word Representation) 기법 개발
[참고]
- Stanford Univ. CS224n, “Natural Language Processing with Deep Learning”, 2019
- WikiDocs, “딥 러닝을 이용한 자연어 처리 입문”, 2020
About The Author
도리
One Comment
감사히 잘 봤습니다.