2018년 12월 17일
스파크 (Apache Spark)
1. 범용 분산 플랫폼, 스파크
(1) 스파크의 개념
- 디스크 I/O를 효율화하고 데이터 분석 작업에 용이한 인메모리 컴퓨팅 기반 데이터 분산처리 시스템
(2) 스파크의 특징
| HDFS 사용 | – 하둡의 파일시스템 기반 동작 |
| 직관적 이해 | – 스칼라 기반 최소화 코드로 작성 |
| RDD | – RDD 단위로 데이터 연산을 수행 |
2. 스파크 구조 및 구성요소
(1) 스파크 구조
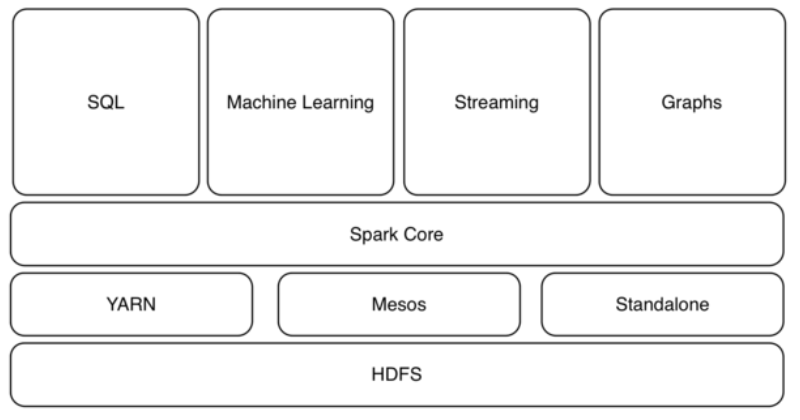
- 스파크는 일괄처리 방식 뿐 아니라 포괄적 분석 기반을 목표로 복수의 프레임워크로 구성
(2) 스파크의 구성 요소
| 구분 | 구성 요소 | 설명 |
|---|---|---|
| 구성 요소 | Spark Core | – 하둡과 같은 일괄처리 담당하며 다른 프레임워크의 기반 |
| SQL | – 데이터웨어하우스 처럼 SQL에서 인터랙피트 분석 가능 | |
| Streaming | – IoT 센서 데이터나 SNS 데이터 등 실시간으로 스트리밍 처리 | |
| 자원 스케줄링 | – 자원 스케줄링 기능(YARN) 사용 – 스케줄링 위해 메소스 계층배치 | |
| 요소 기술 | RDD (Resilient Distribute Dataset) | – 데이터 내장애성 보유 구조 – 데이터 집합의 추상적객체 개념 |
| RDD 연산자 | – RDD에 대한 병렬 데이터 처리 연산 지원 연산자 제공 | |
| 인터랙션 | – 함수형 프로그래밍이 가능하도록 Scala를 사용하여 쉘 사용 | |
| 작업 스케줄링 | – RDD가 변화되는 과정을 그래프로 표현하고 스케줄링 |
3. 스파크와 스톰 비교
| 항목 | 스파크 | 스톰 |
|---|---|---|
| 데이터 처리 | – 일괄 처리 방식 | – 실시간 스트리밍 방식 |
| 업데이트 | – 파일 or 테이블 | – 스트림 (튜플) |
| 컴퓨팅 환경 | – 인메모리 기반 | – 인메모리 기반 |
| 반복 작업 | – 강력한 성능 | – 일반적 수준 |
| 프로그램언어 | – Scala | – Clojure |
| 사용 환경 | – 반복 & 많은 연산 | – 응답시간↓, 다양질의 |