2026년 6월 20일
유니코드 (Unicode)
1. 전 세계 문자 인코딩 표준, 유니코드 (Unicode)의 개요
| 코드표 샘플 |  | |
|---|---|---|
| 개념 | 전 세계 문자를 고유 코드포인트에 맵핑하고 UTF-8 등으로 가변 인코딩하는 문자 인코딩 표준 | |
| 필요성 | 다국어 동시 표현 | – 하나의 웹페이지나 DB 내 한국어, 영어, 중국어, 아랍어 등 다국어와 이모지(Emoji)까지 인코딩 전환 없이 동시 표현 가능 |
| 플랫폼 호환성 확보 | – 플랫폼별 문자 코드 해석 차이로 인한 데이터 왜곡 현상 근본 해결 – 모든 시스템이 고유 코드포인트로 소통하므로 데이터 무결성 유지 | |
| 코드 표준화로 개발비용 절감 | – 웹 표준(HTML5), JSON, XML 등 대부분 유니코드(UTF-8) 기본 채택 – 국가별 문자열 변환 로직 구현 불필요, 개발 및 데이터 교환 효율성 향상 | |
- 유니코드는 전 세계 모든 문자에 대해 플랫폼, 프로그램, 언어에 관계 없이 일관되게 사용하도록 설계된 산업 표준으로, 유니코드 컨소시엄에서 제정, ISO 10646 문자 집합, 인코딩 방법, 문자 정보 DB, 알고리즘 등 포함
- UTF (Unicode Transformation Format): 유니코드 변환 형식 (UTF-8, UTF-16, UTF-32 등)
2. 유니코드의 핵심 요소 및 ASCII 코드와 비교
(1) 유니코드의 핵심 요소
| 구분 | 핵심 요소 | 역할 |
|---|---|---|
| 추상화 맵핑 | 추상 문자 (Abstract Character) | – 정보 부호화(Encoding)의 대상이 되는 문자의 기본 단위 – 알파벳 ‘A’, 한글 ‘가’, 줄바꿈(LF), 이모지(Emoji) 등 |
| 코드 포인트 (Code Point) | – 하나의 추상 문자에 1:1로 대응하여 할당된 고유한 정수 값 – U+XXXX (16진수) 형태로 표기, 0 ~ 0x10FFFF 주소를 할당 | |
| 물리적 처리 규격 | 인코딩 형식 (UTF 선택) | – 코드 포인트를 물리적인 bit/byte 시퀀스로 변환 – 웹 전송(UTF-8), 메모리 처리(UTF-16) 등 선택 적용 |
| 정규화 형식 (NormalizationForm) | – byte 시퀀스가 다른 문자열을 동일 이진 표현 방식으로 변환 – NFC(완성형 문자 중심 기법)와 NFD(자소 분리 중심 기법) | |
| 공간 구조 및 확장 (UTF-16) | 코드 평면 (Plane) | – 유니코드 전체 공간을 65,536개씩 묶은 논리적 구역(0~16) – 제0평면: BMP(기본 다국어 평면), 1~16평면: 보충 평면 |
| 서로게이트 쌍 (Surrogate Pairs) | – UTF-16 인코딩에서 보충 평면 문자 표현용 코드 포인트 쌍 – 상위(2byte)/하위(2byte) 총 4바이트로 하나의 문자를 조합 |
(2) ASCII 코드와 유니코드 비교
| 비교 항목 | 아스키 코드 (ASCII Code) | 유니코드 (Unicode) |
|---|---|---|
| 표준 | ASCII | ISO/IEC 10646 |
| 할당 크기 | 7비트 (하드웨어 처리 위해 1바이트 저장) | 21비트 코드 공간 (물리 저장은 1~4바이트 가변) |
| 표현 문자 수 | 128개 | 1,114,112개 (지속 확장 중) |
| 표현 범위 | 영문 대소문자, 숫자, 기본 문장부호, 제어 문자 | 전 세계 모든 현대/고대 문자, 특수 기호, 이모지(Emoji) |
| 구조적 특징 | 문자 형태와 저장 바이트 값 일치 (1:1) | 문자 코드와 저장 방식(인코딩) 분리 |
| byte 동기화 (Sync) | 불필요 (항상 1바이트) | Self-Synchronizing |
| 포인터 연산 | 매우 단순 (ptr++) | 다소 복잡 (문자 경계 정규 표현식 또는 디코딩 알고리즘 필요) |
| 메모리 패딩 오버헤드 | 없음 (데이터 효율 100%) | 영문은 100%, 한글/한자는 3바이트 소모 |
| 유효성 검증 (Validation) | MSB가 1인지만 체크 | 규정된 비트 패턴(110x, 10xx 등)이 허용된 코드포인트 범위 내 존재여부 검증 |
- 유니코드는 ASCII 코드 전체를 포함하며, OS(Windows, Mac, Linux), 디바이스, DB마다 문자 코드를 다르게 해석해 텍스트가 외계어처럼 변하던 데이터 왜곡(Mojibake) 현상을 근본적으로 해결
3. 유니코드 인코딩 절차, 변환표 및 인코딩 사례
(1) 유니코드 인코딩 절차
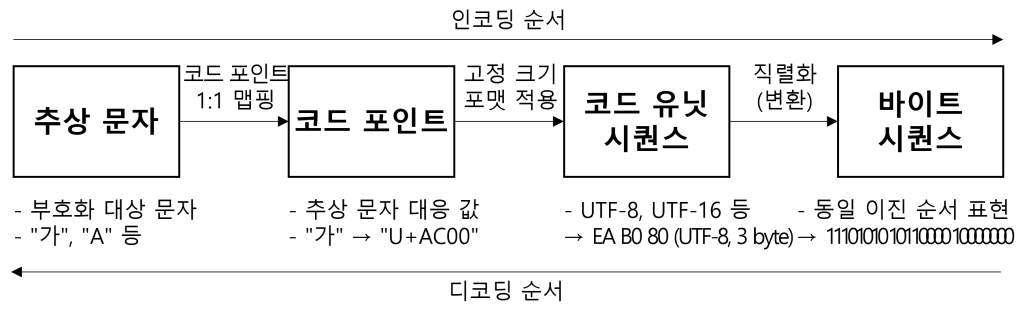 |
(2) 유니코드 변환표
- 코드 포인트 → 코드 유닛 시퀀스 변환표(UTF-8 기준, U+uvwxyz)
| 주요 언어 및 문자 | 문자당 크기 | 코드 포인트 범위 | 코드 유닛 시퀀스 (Byte 1 ~ 4) |
|---|---|---|---|
| 기본 기호(ASCII) 라틴 문자(알파벳) | 1 byte | U+0000 ~ U+007F | 0yyyzzzz |
| 라틴 문자(확장) 그리스어, 아랍어 등 | 2 byte | U+0080 ~ U+07FF | 110xxxyy 10yyzzzz |
| 한국어, 중국어 일본어, 힌디어 등 | 3 byte | U+0800 ~ U+FFFF | 1110wwww 10xxxxyy 10yyzzzz |
| 이모지, 고대 문자 특수 기호 등 | 4 byte | U+10000 ~ U+10FFFF | 11110uvv 10vvwwww 10xxxxyy 10yyzzzz |
(3) 유니코드 인코딩 사례
① 추상 문자
| “안녕하세요” 한국어 문자를 UTF-8로 인코딩 |
② 코드 포인트로 변환
| 추상 문자 | 코드 포인트 |
|---|---|
| “안” | U+C548 |
| “녕” | U+B155 |
| “하” | U+D558 |
| “세” | U+C138 |
| “요” | U+C694 |
- 코드 포인트 테이블 참조: https://www.unicode.org/charts/
③ 코드 유닛 시퀀스로 변환
- 3 byte 변환표 적용: 1110wwww 10xxxxyy 10yyzzzz
| 코드 포인트 | 코드 포인트 이진수 | 코드 유닛 시퀀스 |
|---|---|---|
| U+C548 | 1100 0101 0100 1000 | 11101100 10010101 10001000 (EC 95 88) |
| U+B155 | 1011 0001 0101 0101 | 11101011 10000101 10010101 (EB 85 95) |
| U+D558 | 1101 0101 0101 1000 | 11101101 10010101 10011000 (ED 95 98) |
| U+C138 | 1100 0001 0011 1000 | 11101100 10000100 10111000 (EC 84 B8) |
| U+C694 | 1100 0110 1001 0100 | 11101100 10011010 10010100 (EC 9A 94) |
④ 바이트 시퀀스로 변환
- UTF-8은 BOM (Byte Order Mark) 구분이 불필요하므로 그대로 적용
| 코드 유닛 시퀀스 | 바이트 시퀀스 |
|---|---|
| 11101100 10010101 10001000 (EC 95 88) | 11101100 10010101 10001000 (EC 95 88) |
| 11101011 10000101 10010101 (EB 85 95) | 11101011 10000101 10010101 (EB 85 95) |
| 11101101 10010101 10011000 (ED 95 98) | 11101101 10010101 10011000 (ED 95 98) |
| 11101100 10000100 10111000 (EC 84 B8) | 11101100 10000100 10111000 (EC 84 B8) |
| 11101100 10011010 10010100 (EC 9A 94) | 11101100 10011010 10010100 (EC 9A 94) |
⑤ 최종 이진 데이터
- 바이트 시퀀스를 순차 나열
| 11101100 10010101 10001000 11101011 10000101 10010101 11101101 10010101 10011000 11101100 10000100 10111000 11101100 10011010 10010100 (총 15 byte) |
- 최근 유니코드는 전 세계 웹페이지의 대부분을 점유하며 문자 인코딩 표준을 선도하고 있으며, 문자 데이터의 저장부터 전송, 사용과 AI 오케스트레이션까지 디지털 표현의 핵심축으로 진화중
- 특히 현재 많은 대규모 언어 모델(LLM)이 영문 대비 한글, 한자, 아랍어 등의 유니코드 가변 바이트 문자를 처리할 때 더 많은 토큰을 소비하여 비용 왜곡이 발생하고 있어 문자열의 의미론적 단위의 바이트 연산 효율성을 고려하는 방향으로 고도화 필요
[참고]
- Unicode Consortium, The Unicode Standard Core Specification Version 17.0, 2025.9