2019년 1월 14일
협업 필터링 (Collaborative filtering)
I. 개인화 서비스를 위한 추천시스템의 개요
가. 추천시스템의 정의
- 개인 맞춤형 서비스 제공 위해 구매패턴 등 과거 데이터를 분석하여 상품을 추천하는 시스템
나. 추천시스템의 필요성
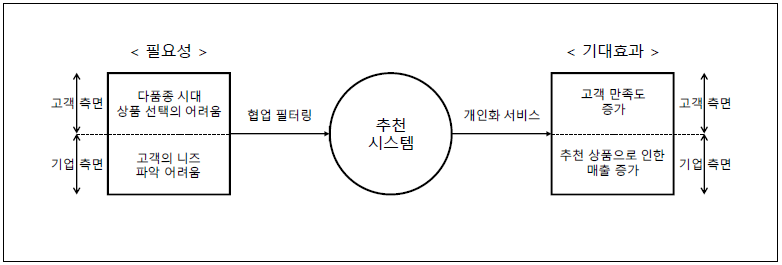 |
- 적중률을 높이기 위해 데이터에 대한 메타 정보 관리와 분석 알고리즘이 중요, 추천시스템 분석 알고리즘 중 가장 대표적 알고리즘으로 협업 필터링
II. 협업 필터링의 개념 및 유형
가. 협업 필터링의 개념
- 누적된 대규모의 데이터를 활용하여 분류된 데이터의 기준 기반 새로운 데이터에 대입하여 분류하는 방법
나. 협업 필터링의 유형
| 항목 | 사용자 기반 | 아이템 기반 |
|---|---|---|
| 개념 | – 선호 성향이 비슷한 사용자들을 같은 그룹화, 동일 그룹 선호 상품 추천 | – 과거 구매 아이템 기반 아이템과 선호 연관성 높은 다른 아이템 추천 |
| 설명 | 사용자1: A, B, C, D 구매 사용자1, 3 구매패턴 유사 | 사용자1: A, B, C, D 구매 아이템A와 C 연관성 높음 |
| 사례 | SNS의 친구 추천 | 아마존, 넷플릭스 상품추천 |
- 선호 성향이 비슷한 다른 사용자 또는 과거 구매 아이템과 연관성이 높은 아이템은 사용자의 개별 아이템에 대한 선호도 기반 다양한 유사도 알고리즘으로 분석
III. 맞춤형 콘텐츠 제공위한 콘텐츠 추천 알고리즘
가. 콘텐츠 추천 알고리즘의 유형
| 구분 | 알고리즘 | 알고리즘 상세 설명 |
|---|---|---|
| 전통적 알고리즘 | 협업 필터링 | – 사용자 행동 분석 기반 추천 – 아이템기반, 사용자기반 분석 |
| 콘텐츠기반 필터링 | – 콘텐츠 내용 분석 기반 추천 – 유클리디언, 코사인 유사도 측정 | |
| 최신 알고리즘 | 모델기반 협력 필터링 | – 자료 내 사용자 패턴기반 추천 – LDA, 베이지안 네트워크 |
| 딥러닝 기반 필터링 | – 구글 Text 자동 생성 기술 – 지도/비지도학습 기반 알고리즘 |
- 최근 Deep Learning 기반 KNN, DBSCAN, SVM 등 AI기술 적극 활용하여 필터링 기법 개발 추세
나. 추천 시스템 유사도 알고리즘
| 알고리즘 | 측정기준 | 측정 방법 |
|---|---|---|
| 유클리디안 유사도 | 유사도 거리 | – 선호도를 벡터값으로 표현하여 두 지점 간 거리 계산, 유사도 측정 |
| 코사인 유사도 | 벡터 각도 | – 선호도를 벡터 각도 코사인 계산하여 유사도 측정, 방향 확인 |
| 피어슨 유사도 | 경향성 수치 | – (X,Y 함께 변화)/(X,Y 따로 변화) – X, Y 상관 관계 해석, 경향성 측정 |
| 자카드 유사도 | 선호도 수치 | – (X, Y 교집합 수)/(X, Y 합집합 수) – 선호도를 알기 어려울 경우 사용 |
- 상관 분석을 하는 대상에 따라 적절한 유사도 알고리즘 사용
IV. 추천 시스템 운영 시 고려사항
가. 추천 시스템의 한계
| 구분 | 한계점 | 한계점 세부 설명 |
|---|---|---|
| 협업 필터링 | 콜드 스타트 | – 새로운 항목 추천 한계 – 초기 정보 부족의 문제점 |
| 계산 효율 저하 | – 다수 사용자의 경우 비효율 – 행렬 분해 시 장기간 계산 | |
| 롱테일 문제 | – 비대칭적 쏠림현상 발생 – 관심 저조 항목 정보 부족 | |
| 콘텐츠기반 필터링 | 메타정보 함축 한계 | – 한정된 메타정보로 사용자와 상품의 프로파일 함축 불가 |
| 추천시스템 공통 문제 | 필터버블 | – 전체 정보 접근 기회 박탈 – 정보의 편향적 제공, 양극화 |
나. 추천 시스템 한계의 극복 방안
| 한계점 | 극복 방안 | 상세 방안 |
|---|---|---|
| 콜드스타트 | – 딥러닝 기반 필터링 | – 항목 자체 내용 분석 기반 – KNN, DBSCAN 등 AI기술 |
| 계산 효율 저하 | – 병렬 컴퓨팅 | – 행렬 계산 최적화 컴퓨팅 사용 – GPGPU, Grid Computing 등 |
| 롱테일 문제 | – 모델기반 협력필터링 | – 자료 내 사용자 패턴기반 추천 – LDA, 베이지안 네트워크 |
| 메타정보 함축한계 | – 협업 필터링 유사도 계산 | – 서로 다른 분야 수치 계산 – 피어슨, 자카드 유사도 측정 |
| 필터버블 | – RAA – 플립피드 | – 경고 푸시, 반대 콘텐츠 노출 – 딥러닝, SNS 타임라인 분석 |
About The Author
도리
3 Comments
좋은 글 감사합니다. 한계점과 극복방안에 대해 잘 정리되어있어서 좋았습니다.
정리 엄청 잘 해주셔서 , 이해가 잘 되네요 감사합니다.