2022년 5월 29일
IMDG (In-Memory Data Grid)
1. IMDG(In-Memory Data Grid)의 개요
(1) IMDG의 개념
- 대용량 데이터 관리 위해 다수의 컴퓨터 메모리를 그리드로 연결하여 주 데이터 저장소로 활용하는 고가용성 및 확장성 제공 분산 메모리 시스템
(2) IMDG의 특징 및 요구사항
| 특징 | 요구사항 | 세부 사항 |
|---|---|---|
| 고가용성 | 복제 | 데이터 복제를 통한 이중화 구성 |
| 지속적 관리 | Write-through, Write-behind, DRM | |
| 확장성 | 파티셔닝 | 데이터 분할 규칙에 따른 분산 저장 |
| 이벤트 | 분산 저장소에 대한 데이터 동기화 | |
| 데이터 일관성 | 트랜잭션 | ACID 트랜잭션 보장 |
| 락킹 | 트랜잭션 보장을 위한 락 관리 기능 | |
| 고성능 | 분산 데이터베이스 | 코드/데이터의 분산저장 및 활용 |
| Map-Reduce | Map-Reduce 방식의 데이터 병렬 처리 | |
| 관리 효과성 | 보안성 확보 | 접근 보안 및 암호화 |
| 콘솔 제공 | 모니터링 및 관리 툴 제공 | |
| 호환성 | NoSQL 연동 | 빅데이터 DBMS와 연계 |
| 쿼리 언어 | SQL 같은 스크립트 언어 지원 |
- DBMS에서 발생하는 부하를 IMDG 서버로 분산하여 병목 구간 해소
2. IMDG의 아키텍처 및 기술요소
(1) IMDG의 아키텍처
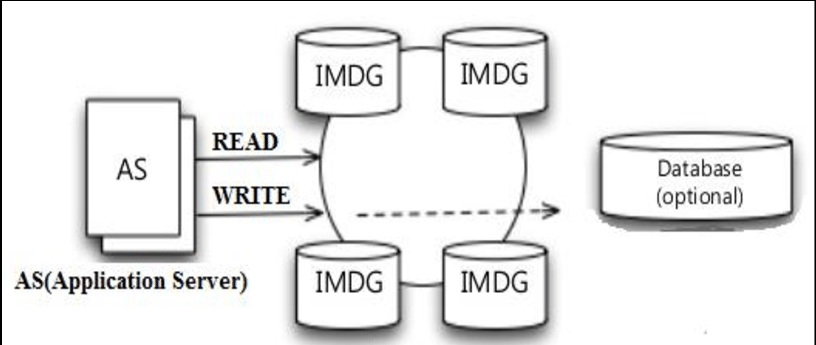 |
- 데이터를 다수 서버 메모리에 분산 저장하여 Replication과 Synchronization을 통해 고가용성, 확장성 및 READ/WRITE 성능 확보
(2) IMDG의 기술요소
| 구분 | 기술요소 | 역할 |
|---|---|---|
| 데이터 처리 | Key-Value | 키(Key) 기반 데이터 분산 저장 |
| Collection API | 다수 노드 대상 HashMap, HashSet 사용 | |
| 트랜잭션 기술 | Distributed Event | Publish 순서 보장 Topic 읽기 가능한 분산 메시지 큐 |
| Distributed Lock | 다수 분산 시스템에서 단일 Lock 기반 동기화 | |
| Transactions | 신뢰성 확보를 위한 Commit/Rollback | |
| Off-heap Memory | Full GC 처리시간 향상을 위한 JVM 메모리 | |
| 분산 기술 | Clustering | 다수 서버 메모리를 단일 메모리 저장소로 구성 |
| Replication | 다수 서버에 데이터 분산하여 데이터 유실방지/복구기능 | |
| Synchronize | 사용자 요청은 다수 서버에서 병렬 처리 |
- Memory 제한을 High Scalability 기반 극복하여 고가용성과 확장성 보장
3. IMDG와 데이터베이스/캐시 시스템 비교
(1) IMDG와 데이터베이스 비교
| 비교 항목 | IMDG | RDBMS | NoSQL |
|---|---|---|---|
| Scale-Out(확장성) | 가능 | 불가 | 가능 |
| Availability(가용성) | 높음 | 낮음 | 높음 |
| Consistency(일관성) | 확보 | 확보 | 미확보 |
| Persistence(영속성) | 미확보 | 확보 | 확보 |
(2) IMDG와 캐시 시스템 비교
| 항목 | IMDG | 캐시 시스템 |
|---|---|---|
| Read | 항상 IMDG에서 Read하므로 성능 향상 | 데이터가 캐시에 존재 시 성능 향상 데이터가 캐시에 미존재 시 성능 향상 없음 |
| Write | Asynchronous Write 지원 시 성능 향상 | 영구 저장소에 Write하므로 성능 향상 없음 |
- 데이터 마이그레이션 가능 여부, 신뢰성 보장, 복제 기능 제공 등의 차이점 존재
[참고]
- LGCNS, “In-Memory Computing 기술현황 및 전망”, 2013.1
- 삼성SDS, “시스템 성능 개선을 위한 In-Memory 기술 활용 ‘In-Memory Data Grid 활용 사례'”, 2018.9
About The Author
도리
One Comment
글 잘보았습니다. 감사합니다.