2018년 11월 27일
NoSQL (Not only SQL)
1. 분산 환경 최적 DBMS, NoSQL의 개념
- 테이블-컬럼 스키마 없이 분산 환경에서 Key-Value 기반 단순 검색 및 추가 작업이 용이한 DBMS
2. NoSQL 데이터 모델 구조
| 모델 구조 | 개념도 | 설명 |
|---|---|---|
| Key/Value Store | Key/Value Model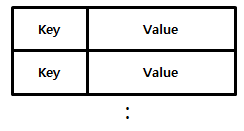 Column Family Model | – Unique한 Key에 하나의 Value 형태 모델 – Column Family Key 내 (Column, Value) 조합으로 된 여러 필드를 갖는 모델 |
| Ordered Key/Value Store | 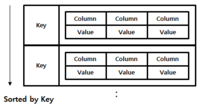 | – Key/Value Store의 확장된 형태로, 데이터가 Key 순서로Sorting |
| Document Key/Value Store | 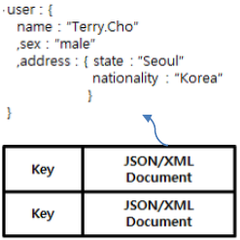 | – 저장되는 Value 데이터가 Document 타입 – XML, JSON, YAML 등 구조화된 타입으로 복잡한 계층 구조 표현 |
3. NoSQL과 관계형DB 비교
| 항목 | NoSQL | 관계형DB |
|---|---|---|
| 데이터 모델 | – Scheme-less – Key-Value 관계 | – 행/열로 구성 – 스키마, 인덱스 등 |
| ACID 속성 | – 유연한 데이터구조 – ACID 속성 절충 | – ACID 속성이 중요 (원자, 일관, 독립, 영속성) |
| 확장 | – Scale-Out 방식 – 하드웨어 분산 | – Scale-Up 방식 – 하드웨어 집적도 |
4. NoSQL의 특징
| 구분 | 특징 | 설명 |
|---|---|---|
| 데이터 베이스 측면 | 스키마 유연성 | – 컬럼 등 스키마 변경 자유로움 – 재가동 없이 스키마 구조 변경 |
| 복잡 쿼리 불필요 | – 조인 기능 없음 – 조인에 따른 쿼리 복잡성 해소 | |
| 트랜잭션 보장 | – Column Family, Super Column – 트랜잭션 수행이 보장 | |
| 확장성 | – 데이터량 증가에 따른 데이터베이스 확장성 우선 지원 | |
| 데이터 모델 측면 | 비 관계형 모델 | – 데이터 간 관계 정의 불가 – 단순, 명료한 데이터 모델 |
| 조회 성능 향상 | – 단일테이블 접근 필요 정보 확보 – 조인이 불필요하여 성능 향상 |
- 단순 검색 및 추가 작업에 최적화되어 응답 속도, 처리 효율 측면에서 뛰어난 성능 발휘
5. NoSQL 데이터 모델링 패턴 및 절차
(1) NoSQL 데이터 모델링 패턴
| 모델링 패턴 | 핵심 기능 | 패턴 설명 |
|---|---|---|
| Denormalization (비정규화) | 중복 저장 역정규화 유사 | – 동일데이터 중복 저장 – 한번의 I/O로 조회 |
| Aggregation | 유연한 스키마 (Schema-less) | – row의 key 동일 시 데이터 타입 제약없음 |
| Application Side Join | Client 측면 Join 처리 | – 조인 필요 시 Client APP 단 조인 처리 |
| Atomic Aggregation | 단일 테이블 통합 | – 일관성 보장 위해 단일 테이블로 통합 |
| Index Table (단일 인덱스) | 인덱스 생성 | – 인덱스 미지원하므로 별도 인덱스 생성 |
| Composite Key Table | 복합 인덱스 생성 | – 단일 인덱스 모델에서 복합 인덱스 필요 시 |
(2) NoSQL 데이터 모델링 절차
| # | 절차 | 세부 절차 설명 |
|---|---|---|
| 1 | 도메인 모델 파악 | – 저장 위한 도메인 파악 – 개체 및 관계 분석, ERD 도식화 |
| 2 | 쿼리결과 디자인 | – 도메인 모델에 따른 쿼리 결과 – 데이터 출력 내용 기반 디자인 |
| 3 | 패턴 이용 모델링 | – Put/Get 기반 데이터 가공 – NoSQL 내 테이블로 재정의 |
| 4 | 기능 최적화 | – RDBMS의 인덱스 개념 사용 위해 Secondary Index로 기능 최적화 |
| 5 | 후보 선정 /테스트 | – 구조 및 특성 분석, 부하테스트 – 후보 중 적절한 솔루션 선택 |
| 6 | 선정 모델 최적화 | – 선정 모델 기반 모델링 최적화 – I/F 설계 및 하드웨어 디자인 |