2023년 6월 2일
빅엔디언(Big Endian), 리틀엔디언(Little Endian)
1. 데이터 저장 순서, 빅 엔디언과 리틀 엔디언의 개념
| 빅 엔디언(Big Endian) | 리틀 엔디언(Little Endian) |
|---|---|
| 여러 개의 연속된 데이터를 1차원의 기억장치 최상위 공간(MSB)부터 차례로 배열하는 기법 | 여러 개의 연속된 데이터를 1차원의 기억장치 최하위 공간(LSB)부터 차례로 배열하는 기법 |
- IP 주소와 같은 네트워크 환경과 IBM 등 RISC 기반 컴퓨팅 환경에는 빅 엔디언을 주로 사용하고, Intel x86, AMD 등의 컴퓨팅 환경에는 리틀 엔디언을 주로 사용
2. 빅 엔디언과 리틀 엔디언의 저장 방식 및 특징 비교
(1) 빅 엔디언과 리틀 엔디언의 기억장치 저장 방식 비교
| 빅 엔디언의 기억장치 저장 방식 | 리틀 엔디언의 기억장치 저장 방식 |
|---|---|
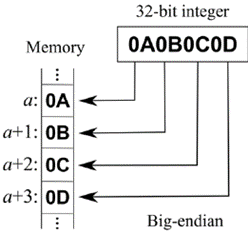 – 최상위(MSB, Most Significant Bit)부터 저장 | 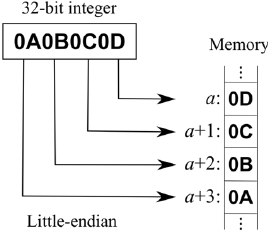 – 최하위(LSB, Least Significant Bit)부터 저장 |
- 예를 들어 “2진수: 0001” bit order로 저장 시, 빅 엔디언 방식 저장 시 “10진수: 1”을 의미하고, 리틀 엔디언 방식 저장 시 “10진수: 8”을 의미하며, 실제 데이터 저장 시 Byte 단위로 저장
(2) 빅 엔디언과 리틀 엔디언의 특징 비교
| 비교 항목 | 빅 엔디언 | 리틀 엔디언 |
|---|---|---|
| 저장 방식 | – 최상위 비트(MSB) 부터 저장 | – 최하위 비트(LSB) 부터 저장 |
| 계산 방식 | – 역방향 계산으로 추가비트 필요 | – 올림 수(carry) 발생 시 쉽게 처리 |
| 데이터 비교 | – 순차 스택 삽입으로 비교적 고성능 | – 역순 스택 삽입으로 성능 저하 |
| 확장 방식 | – 확장 시 여분의 연산 필요 | – 임시적인 축소 및 확장에 유연 |
| 디버깅 | – 메모리에 적재된 값 분석이 용이함 | – 가시적 판단에 대한 난해성 증가 |
| 네트워크 처리 | – 순차적 바이트 오더링 수행 | – 전송을 위해 바이트 재정렬 필요 |
| 활용 사례 | – RISC 아키텍처 기반 프로세서 – 네트워크 주소 및 프로토콜 | – Intel x86 아키텍처 기반 프로세서 |
- 빅 엔디언의 경우 데이터가 정렬되어 있어 순방향 읽기 성능이 높고, 리틀 엔디언의 경우 역순으로 정렬된 데이터를 순차 접근하며 더해가는 산술 연산 성능이 높음
3. 빅 엔디언과 리틀 엔디언의 장단점 비교
| 비교 항목 | 빅 엔디언 | 리틀 엔디언 |
|---|---|---|
| 장점 | – 데이터 비교, 읽기 연산 우수한 성능 – 디버깅 과정에 편의성 제공 | – 산술 연산에 우수한 성능 – 타입을 읽거나 형 변환 시 우수한 성능 |
| 단점 | – 산술 연산 시 오버헤드 발생 가능 – 타입을 읽거나 형 변환 시 성능 저하 | – 네트워크 전송 시 바이트 재정렬 필요 – 오류 발생 시 디버깅 가독성 저하 |
- 빅 엔디안과 리틀 엔디안의 장점을 고루 활용하기 위해 두 방식 중 하나를 선택할 수 있는 바이 엔디언(Bi-Endian) 방식과 1~2 바이트 단위로 빅 엔디언과 리틀 엔디언을 교차하여 사용하는 미들 엔디언(Middle-Endian) 방식 존재