2020년 12월 29일
머신러닝 파이프라인 (Machine Learning Pipeline)
I. 머신러닝 파이프라인(ML Pipeline)의 개요
가. 머신러닝 파이프라인의 개념
나. 머신러닝 파이프라인의 필요성
| 머신러닝 자동화 | 머신러닝 모델 전 과정 지속 수행 위한 파이프라인 기반 자동화 |
| 예측 정확성 향상 | 내부 구조 이해를 통한 머신러닝 성능(예측의 정확성) 향상 |
II. 머신러닝 파이프라인의 데이터 처리 흐름과 활동
가. 머신러닝 파이프라인의 데이터 처리 흐름
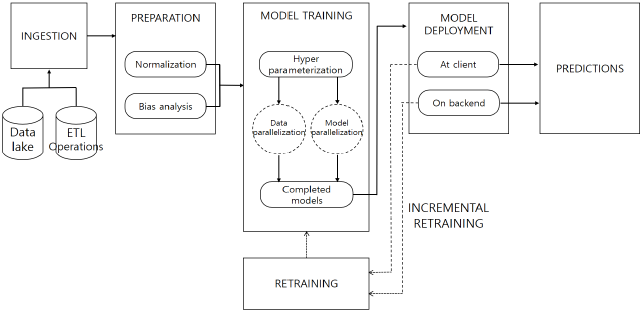 |
나. 머신러닝 파이프라인의 처리 단계 별 주요 처리 활동
| 처리 단계 | 처리 활동 | 세부 처리 방안 |
|---|---|---|
| 데이터 수집 | ETL 적용 | – 기존 데이터 소스에서 데이터 수집 – 다운로드 데이터, 데이터 소스 추출 |
| 데이터 레이크 (Data Lake) | – 다양한 Raw 데이터 실시간 수집, 전처리, 변환, 저장 – Real-time/Batch Data, FTP, SQL/NoSQL, HDFS | |
| 데이터 준비 | 데이터 정규화 (Normalization) | – 사용할 데이터에서 일관성 확보 – K-means 클러스터링의 경우 필수 |
| 편향 분석 (Bias Analysis) | – 모델에 포함된 편향성을 찾아 제거 – 정리된 데이터의 편향성 제거 추측 금지 | |
| 모델 교육 | 하이퍼파라미터 (Hyperparameter) 적용 | – 최적 딥러닝 모델 구현 위해 학습률 등 변수 설정 – 학습률, 손실함수, 정규화, 미니배치, 훈련횟수 |
| 병렬처리 (Parallelism) | – 처리 성능 향상 위해 모델 분산 컴퓨팅 처리 – GPGPU, MXNet, TensorFlow, Torch 프레임웍 | |
| 예측 제공 (머신러닝 모델 배치) | 클라우드 호스팅 머신러닝 모델 배치 | – 데이터센터에 수신되는 데이터 대상 예측 생성 – RESTful API 기반 클라우드 인스턴스에서 예측 제공 |
| 클라이언트 기반 머신러닝 모델 배치 | – 클라이언트에 교육된 모델 배치 후 주기적 갱신 – 낮은 대역폭, 네트워크 연결 불가 클라이언트 대상 |
- 이상적인 머신러닝 파이프라인 구현을 위해 파이프라인의 모든 단계를 포괄하고 CI/CD 등 끊임 없이 완전한 오픈소스 설계 패턴 필요
III. 머신러닝 파이프라인의 실무 적용 방안
가. 머신러닝 파이프라인 유형에 따른 적용 방안
| 유형 | 적용 방안 | 구현 사례 |
|---|---|---|
| 머신러닝 파이프라인 기본 모델 | 배포, 캐싱, 코드 우선, 재사용 강조 | – Kubeflow Pipeline |
| 데이터 오케스트레이션 | 데이터 중심활동 강력한 데이터 이동 | – Apache Airflow |
| 지속 통합/배포 (CI/CD) | 유용한 활동 지원 승인, 제어 사용, DevOps | – Jenkins |
나. 효과적 머신러닝 파이프라인 적용 방안
| 구분 | 적용 방안 | 구현 사례 |
|---|---|---|
| 개발 용이성 측면 | 프로세스 내 협업 추진 | – 머신러닝 디자인 프로세스의 모든 영역에서 공동작업 수행 |
| 유지관리 측면 | SDK 기반 버전관리, 디버깅 | – RESTful API 기반 파이프라인 트리거 사용, 재사용성, 추적성 확보 |
| 성과 향상 측면 | 머신러닝 성능 품질 향상 | – 중요 영역 분리, 변경 내용 격리 (ISO23053 등) |
- 다양한 상용 및 오픈소스 머신러닝 파이프라인 오케스트레이션 기계 학습 플랫폼 활용
- MS Azure Machine Learning 파이프라인, Amazon SageMaker Pipelines, Kubeflow 등
[참고]
- InfoWorld, “Data in, intelligence out: Machine learning pipelines demystified”, 2018. 8
About The Author
도리
2 Comments
글 잘 읽고 갑니다.
잘 정리된 글 작성해주셔서 감사합니다 🙂