2019년 1월 18일
람다, 카파 아키텍처
I. Polyglot 환경 빅데이터 분석, 람다 아키텍처
가. 람다 아키텍처의 개념
- 데이터 대상 분석 기능 수행 위해 배치, 스피드, 서빙 레이어로 구성된 데이터 분석 아키텍처
나. 람다 아키텍처의 특징
- 범용성, 확장성, 결함허용성
- 전송 지연최소화, 분석 결과 일관성, 성능, 확장의 균형, 정확성
다. 람다 아키텍처의 구성도
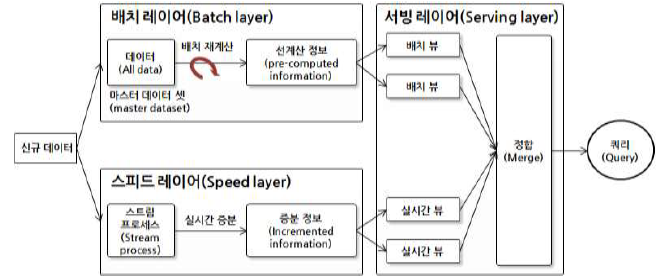 |
- 저장된 데이터를 일괄 처리하는 배치 레이어와 실시간 유입 데이터 처리용 스피드 레이어, 사용자로부터 쿼리 요청 결과 제공 서빙 레이어로 구성
라. 람다 아키텍처 상세 내용
| 구분 | 설명 |
|---|---|
| 레이어 구조 | – 3개 레이어 구조(배치, 스피드, 서빙) |
| 아키텍처 목적 | – 전송 지연 최소화, 일관성, 정확성 제공 |
| 프로세싱 패러다임 | – 배치 + 스트림 조합 (배치 + 실시간) |
| 재작업 패러다임 | – 배치 사이클마다 전체 데이터 재작업 |
| 자원 소비 | – 많음 (배치 사이클 마다 재작업) |
| 신뢰성 | – 배치는 신뢰성, 스트림은 근사치 제공 |
II. 스피드, 서빙 레이어 구조, 카파 아키텍처
가. 카파 아키텍처의 개념
- 데이터 실시간 분석 기능 수행 위해 스피드, 서빙 레이어로 구성된 실시간 데이터 분석 아키텍처
나. 카파 아키텍처의 특징
- 실시간성, 확장성, 결함허용성
- 전송 지연최소화, 분석 결과 일관성, 성능, 확장의 균형, 정확성
다. 카파 아키텍처의 구성도
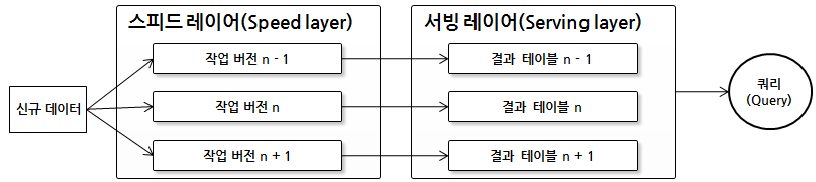 |
- 실시간으로 데이터 처리 위한 스피드 레이어와 쿼리 요청에 대한 결과 제공 서빙 레이어로만 구성
라. 카파 아키텍처 상세 내용
| 구분 | 설명 |
|---|---|
| 레이어 구조 | – 2개 레이어 구조(스피드, 서빙) |
| 아키텍처 목적 | – 레이어간 코드 공유 복잡성 제거 |
| 프로세싱 패러다임 | – only 스트림 (실시간) |
| 재작업 패러다임 | – 코드 변경 시에만 재작업 수행 |
| 자원 소비 | – 증분 데이터만 처리하므로 소비 적음 |
| 신뢰성 | – 일관성있는 스트림 제공으로 신뢰 |
III. 람다 카파 아키텍처 구현 위한 도구 현황
| 구분 | 도구 | 설명 |
|---|---|---|
| 수집 | 카프카 | – 구독/발행 대용량 분산 메시징 – 프로듀서, 브로커, 컨슈머로 구성 |
| 플럼 | – 대규모 분산 데이터 수집, 전송 – 소스, 싱크, 채널로 구성 | |
| 배치 | Map & Reduce | – HDFS 네트워크 디스크 기반 – 하둡에 의존적, 프로그램 복잡 |
| 테즈 | – 로컬 디스크 기반, 배치, 대화형 – 하둡에 의존적, 중간 성능 | |
| 스파크 | – 디스크, 메모리 기반, 준실시간 – 하둡에 독립적, 고성능 | |
| 플링크 | – 디스크, 메모리 기반, 준실시간 – 하둡에 독립적, 고성능 | |
| 스피드 | 스톰 | – 네이티브 스트리밍 방식 – 처리량 적고, 지연시간 낮음 |
| 스파크 스트리밍 | – 마이크로 배치 방식 – 메모리기반 처리량 높고 중간지연 | |
| 삼자 | – 네이티브 스트리밍 방식 – 로그 기반 장애 대응 지원 | |
| 플링크 | – 네이티브 스트리밍 방식 – 체크포인트 기반 장애 대응 지원 | |
| 서빙 | 엘리펀트 DB | – 하둡 기반 키/값 기반 DB – Read-Only, 간단하고 사용 쉬움 |
| HBase | – 컬럼 기반 확장, 분산 DB – 오토 샤딩 지원, 대규모 데이터 처리 | |
| 카산드라 | – 대용량 트랜잭션, NoSQL DB – 수직/수평 확장성 제공 | |
| 하이브 | – 맵리듀스, 디스크 기반 계산 – 느린 처리속도, 읽기 전용 | |
| 임팔라 | – 메모리 기반 계산, MPP 지원 – 자체 실행 엔진, 빠른 성능 | |
| 프레스토 | – 메모리 기반 계산, MPP 지원 – 준실시간 대화형 쿼리 지원, 빠른 성능 |