2024년 4월 10일
AIOps (AI for IT Operations)
1. AIOps (AI for IT Operations)의 개념 및 필요성
| 개념 | IT 운영 관리 자동화 위해 기계 학습 분석을 통해 IT 운영 문제 해결을 자동화하는 App 데이터 관리 및 분석 기술 | |
|---|---|---|
| 필요성 | 기계 학습 기반 IT 운영 자동화/효율화 | 머신러닝 기반 동향 파악, 이상 현상 탐지, 미래 행동 예측, 프로세스 개선 등 IT 운영 자동화, 성능 효율화 |
| 운영 데이터 실시간 분석 기반 성능/용량 관리 개선 | 다양한 소스의 데이터 결합 및 실시간 분석을 통해 IT 운영을 위한 인시던트, 용량, 변경, 성능 관리 개선 | |
| 시계열 운영 데이터 기반 이상 현상 및 패턴 분석 | 현재/과거 데이터 기반 이상 현상 및 패턴을 이벤트와 연결하고, 문제 발생 시 처리 자동화 | |
- 인공지능과 ITOps를 결합하여 IT 운영 문제를 자동으로 파악하고 해결하기 위해 Observe(모니터링), Engage(IT 운영), Act(자동화) 단계 기반 데이터 과학을 적용하여 IT 운영 자동화
2. AIOps의 주요 단계 및 계층 별 기술 요소
(1) AIOps의 주요 단계
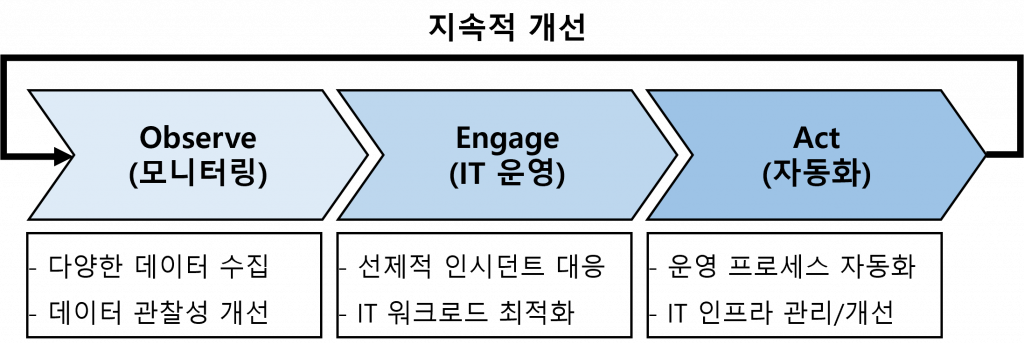 |
(2) AIOps의 단계 별 주요 활동
| 단계 | 주요 활동 | 세부 활동 사항 |
|---|---|---|
| Observe (모니터링) | 운영 데이터 크롤링, 분석 활동 | – 대량의 정보를 실시간으로 수집, 집계, 분석 – 로그 등 데이터에서 패턴 식별, 이벤트 연관 |
| 관측가능성(Observability) 기반 관찰성 개선 | – 메트릭(Metric), 추적(Trace), 로그(Log) 분석 – 시스템의 내부 상태를 이해하고 관찰성 개선 | |
| Engage (IT 운영) | ITSM 적용 | – Best Practice 절차 기반 IT 서비스 관리 – ITIL, CMDB 기반 선제적 인시던트 대응 |
| DevOps 적용 | – 개발/운영팀 정보 공유, IT 워크로드 최적화 – CI/CD, IT 인프라 프로비저닝, 테스트 자동화 | |
| Act (자동화) | 머신러닝 기반 운영 프로세스 자동화 | – ML 기반 보안취약점 조치, 문제 해결 – 하이퍼파라미터 튜닝, ML 모델 훈련/생성 |
| 리소스 효율화 /지속적 개선 | – 운영팀 리소스를 미션 크리티컬 업무에 집중 – 운영 자동화 결과에 따른 보완, 지속적 개선 |
- 다양한 데이터 소스를 수집하여 문제의 근본 원인을 조사하고 잠재적인 문제, 시나리오 예측을 통해 경보 자동화 및 필터링하여 데이터 스트림에서 지속적인 학습을 통해 IT 운영 자동화를 실현
3. AIOps 적용 시 고려사항 및 발전 단계
(1) AIOps 적용 시 고려사항 및 대응 방안
| 고려사항 | 대응 방안 |
|---|---|
| – 운영팀 내 데이터 과학자 부재 – 관련 기술 및 운영팀 역량 확보 필요 – 불충분하거나 품질이 낮은 데이터 – 통찰력 기반 통합된 조치 방법 부재 | – AIOps 플랫폼 및 서비스 활용 – 운영 담당자 교육 및 전문가 참여 – 합성데이터 사용 및 전이 학습 적용 – Playbook 및 Runbook 라이브러리 활용 |
(2) AIOps 향후 발전 단계
 |
- AIOps를 통해 IT 운영 혁신이 가능하고, 향후 예측 분석, 자동화된 원인 분석 및 ChatOps를 통해 복잡한 인프라 관리/최적화하여 IT 운영 경쟁력 확보에 핵심적 역할이 될 것으로 예상됨
[참고]
- Hewlett Packard Enterprise, AIOPS란
- Amazon Web Services, AIOps란
- Pure Storage, AIOps의 미래: 새로운 트렌드