2024년 1월 30일
관측가능성 (Observability)
1. 관측가능성 (Observability)의 개요
(1) 관측가능성의 개념
| 개념도 | 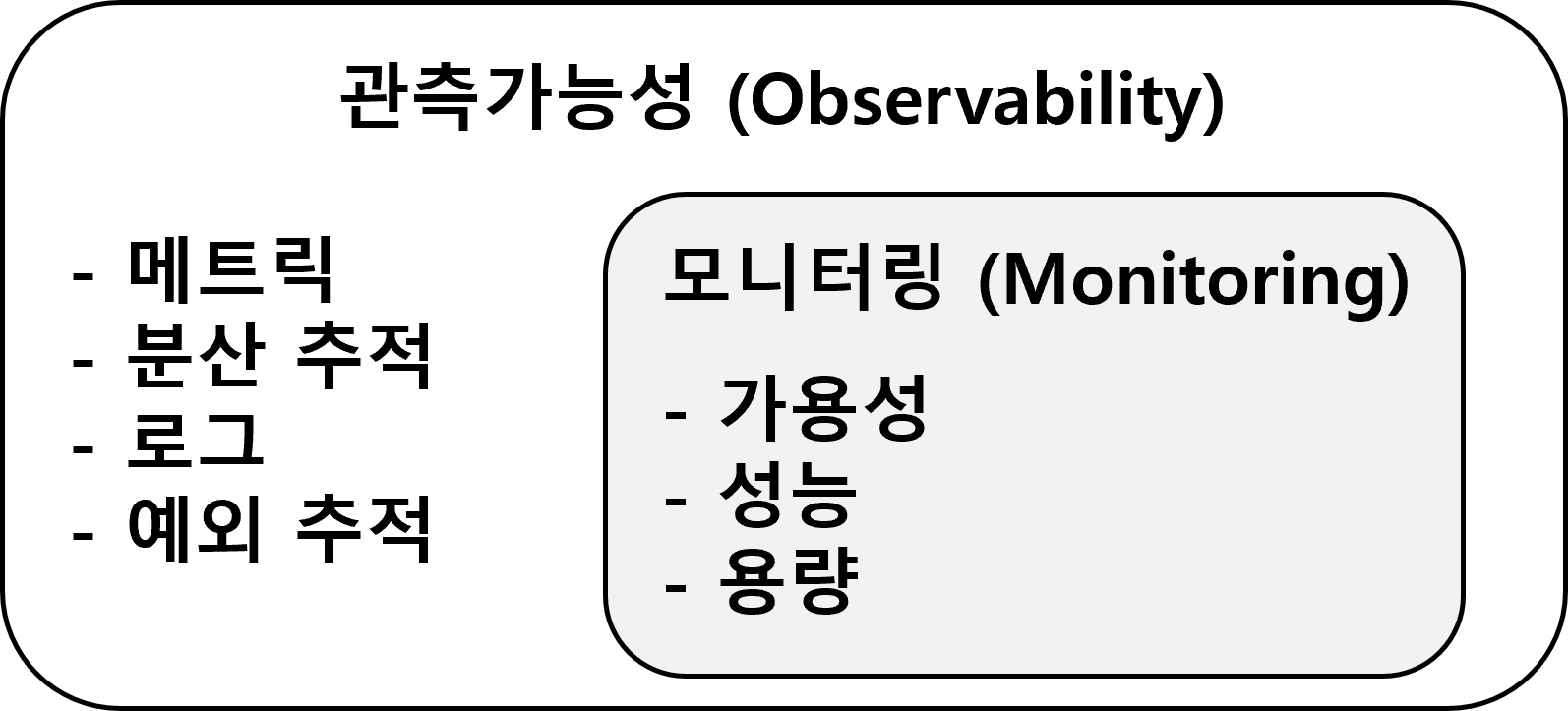 |
|---|---|
| 개념 | 시스템의 문제 해결 및 자동화를 위해 외부 출력값인 메트릭(Metric), 추적(Trace), 로그(Log) 등을 분석하여 시스템의 내부 상태를 이해하고 예측할 수 있는 속성 |
- 제어 이론의 시스템 출력 변수(output variable)를 사용하여 상태 변수(state variable)에 대한 정보를 알아낼 수 있는지를 나타내는 용어에서 출발
(2) 관측가능성과 모니터링의 비교
| 비교 항목 | 관측가능성 | 모니터링 |
|---|---|---|
| 사용 목적 | 복잡한 오류를 추적 | 발생한 오류를 발견 |
| 측정 값 활용 | 시스템 오작동 원인 확인 | 시스템 영향도 식별 |
| 데이터 상관관계 | 데이터의 상관관계 파악 용이 | 데이터의 상관관계 파악 어려움 |
| 분석 대상 | 여러 시스템 연관 분석 | 독립형 시스템 분석 |
| 분석 결과 | 원인 및 과정 | 시점 및 종류 |
- 관측가능성은 외부 출력값을 분석하는 모니터링과 유사하지만 시스템의 내부 상태를 파악하므로 모니터링과는 다르며 관측성, 관찰 가능성이라고도 함.
- 관측가능성은 SRE를 통해 SLO를 정의 및 보호하고 메트릭, 로그, 추적 및 기반 기술을 사용하여 효율적인 시스템 운영 실현
2. 관측가능성의 구성요소와 기반 기술/세부 구현 기술
(1) 관측가능성의 구성요소
| 구성 요소 | 역할 | 출력 형태 |
|---|---|---|
| 메트릭 (Metric) | 일정 시간 동안 측정된 가용성 신호를 집계하고 수치화 | – 큐의 대기 메시지 개수 – CPU/메모리 사용량 |
| 로그 (Log) | App 실행 시 생성되는 텍스트로 JSON 형식이나 비구조적 텍스트 형식 출력 | – 애플리케이션 에러, 경고 – 디버깅 정보 |
| 추적 (Tracing) | 트랜잭션을 처리하는 과정에서 발생하는 세부 정보, 메타데이터 출력 | – 트랜잭션의 시스템이동경로 – 처리 과정의 대기/지연 시간 |
(2) 관측가능성의 기반 기술/세부 구현 기술
| 기반 기술 | 세부 구현 기술 | 메커니즘 |
|---|---|---|
| 트래픽 관리 | eBPF (extended BPF) | – OS 커널 공간 내 샌드박스 프로그램 실행 – Byte Code, Loader, JIT Compiler, Maps, Hook |
| 복원성 패턴 | – 여러 가용 영역에 수평 확장 배포 – 서비스 메시, 재시도, bulkhead, 서킷브레이커 | |
| 오토 스케일링 | 메트릭 측정 | – 오토스케일링 구현 위한 메트릭 요소 측정 – 요청 수, 요청 기간, 동시 요청 등 |
| 메트릭 선정 | – 메트릭 선정, 스래싱 방지, 지연 반응 – 쿠버네티스 훅 핸들러, HPA(Horizontal Pod Autoscaling) | |
| 관측가능성 프로세스 | 관측가능성 운영 프로세스 | 메트릭 분석 → 추적 분석 ↔ 로그 분석 |
| 관측가능성 장애 프로세스 | 장애 발생 → 알람 전송 → 추적 분석 → 로그 분석 | |
| 마이크로 서비스 | CQRS (Command and Query Responsibility Segregation) | – 시스템에서 읽기와 쓰기 분리 – 독립적 크기 조정, 스키마 최적화, 관심사 분리 |
| 파티셔닝 | 샤딩 (수평 파티셔닝) | – 샤딩(파티션) 키 기반 데이터 분산 저장 방식 정의 – 데이터재분배, 특정샤드 집중해소, 조인/비정규화 |
- 관측가능성을 통해 IT 운영 문제를 자동으로 파악하여 해결하는 AIOps를 적용하여 운영 자동화 체계로 발전될 것으로 예상
3. 관측가능성을 활용한 AIOps의 기능과 발전단계
(1) 관측가능성을 활용한 AIOps의 기능
| 데이터 수집 | 머신러닝과 데이터 분석 | 자동화된 진단과 복구 |
|---|---|---|
| – 메트릭 – 로그 – 추적 – 구성 데이터 – 토폴로지 | – 수요 예측 – 이상 탐지 – 위험 탐지 – 트렌드 분석 – 상관관계 분석 | – 문제 진단 – 자동 분류 – 자가 치유 |
(2) 관측가능성을 활용한 AIOps의 발전단계
 |
- 최근 AIOps 도구는 분석 기능까지만 제공하고 있으나, 향후 문제 발생 시 원인 분석과 자가 치유까지 완전한 자동 운영 워크플로우 실현 가능할 것으로 예상
[참고]
- 제이펍, 모니터링의 새로운 미래 관측가능성